





Handling an incident
Contents
The TL;DR
- If you get paged, acknowledge the page and look at the associated metrics - if it looks even slightly bad and not recovering - CREATE AN INCIDENT
- If you notice something broken with the app (not just a bug) - CREATE AN INCIDENT
- If you are not sure - CREATE AN INCIDENT
- How?
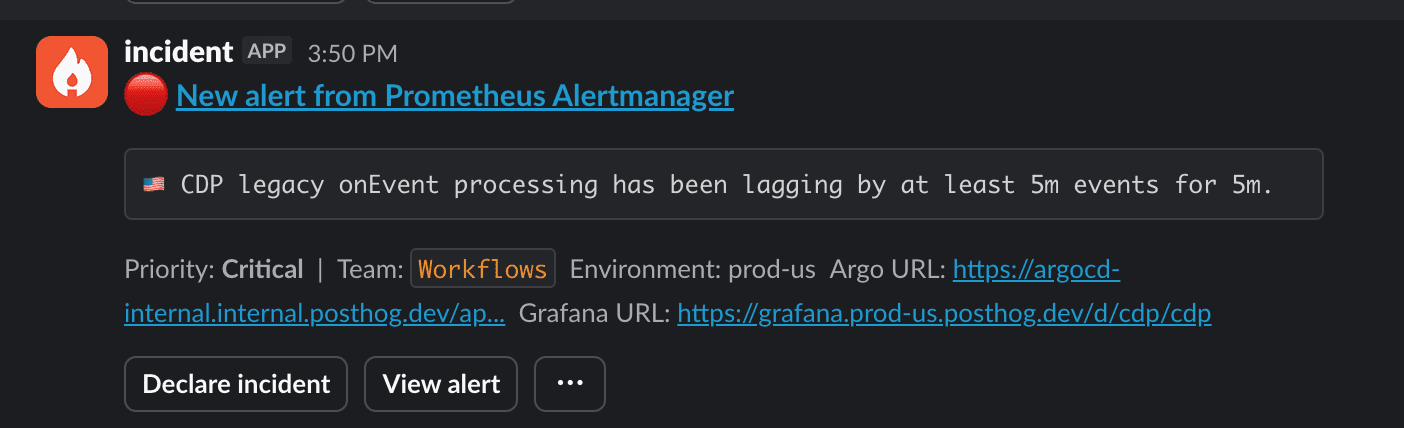
- Click the
Declare incidentbutton on an alert or do/incin any slack channel
- Click the
- What?
- Join the incident channel
- Assign yourself as lead (you can always re-assign later)
- Share whatever info you have at that time
- Escalate by bringing in the relevant team, engineers or via incident.io using the options a the top of the channel
- Update the statuspage if there is any noticeable impact to users
Raising an incident
Incidents are going to happen. If you'd rather watch a Loom, check out an incident drill Loom recording.
Anyone can declare an incident and, when in doubt, you should always raise an incident. We'd much rather have declared an incident which turned out not to be an incident. Many incidents take too long to get called, or are missed completely because someone didn't ring the alarm when they had a suspicion something was wrong. It's always better to sound an alarm than not.
To declare an incident, type /incident anywhere in Slack. This creates a new dedicated channel for the incident and add a few stakeholders. It will trigger an alert in the #incidents channel so everyone else can be aware. Declaring an incident doesn't trigger any external notifications.
Once an incident is raised an automatic workflow begins that will help you summarize the issue and escalate it appropriately.
Some things that should definitely be an incident
us.posthog.com(PostHog Cloud US) oreu.posthog.com(PostHog Cloud EU) being completely unavailable (not just for you)- No insights can be created
- Feature flags are not being returned at all, or
/flagsis down - Any feature is 'down' and users are unable to access their existing data through it (this can be a bug and doesn't have to be an infra incident)
- Various alerts defined as critical, such as disk space full, OOM or >5 minute ingestion lag
Things that shouldn’t be an incident
- Insights returning incorrect data
- Events being < 5-10 minutes behind (E2E ingestion lag)
- Unable to save insights, create feature flags
- Expected disruption which happens as part of scheduled maintenance
Planning some maintenance? Check the announcements section instead.
Security-specific guidance
Security incidents can have far-reaching consequences and should always be treated with urgency. Some examples of security-related issues that warrant raising an incident include:
- Unauthorized access to systems, data, or user accounts
- Detection of malware, ransomware, or other malicious software on company systems
- Suspicious activity on production infrastructure, such as unexpected user logins, privilege escalations, or resource consumption spikes
- Discovery of exposed credentials, sensitive data, or secrets in logs, repositories, or public forums
- Receiving a credible report of a vulnerability or exploit affecting company systems
When in doubt, err on the side of caution and raise the incident and escalate early! Better to be safe than sorry.
Need to make a security advisory? We have a page for that with more detail on the process for security vulnerabilities.
Incident severity
Please refer to the following guidance when choosing the severity for your incident. If you are unsure, it's usually better to over-estimate than under-estimate!
Minor
A minor-severity incident does not usually require paging people, and can be addressed within normal working hours. It is higher priority than any bugs however, and should come before sprint work.
Examples
- Broken non-critical functionality, with no workaround. Not on the critical path for customers.
- Performance degradation. Not an outage, but our app is not performing as it should. For instance, growing (but not yet critical) ingestion lag.
- A memory leak in a database or feature. With time, this could cause a major/critical incident, but does not usually require immediate attention.
- A low-risk security vulnerability or non-critical misconfiguration, such as overly permissive access on a non-sensitive resource
If not dealt with, minor incidents can often become major incidents. Minor incidents are usually OK to have open for a few days, whereas anything more severe we would be trying to resolve ASAP.
Major
A major incident usually requires paging people, and should be dealt with immediately. They are usually opened when key or critical functionality is not working as expected.
Major incidents often become critical incidents if not resolved in a timely manner.
Examples
- Customer signup is broken
- Significantly elevated error rate
- A Denial of Service (DoS) attack or other malicious activity that affects system availability
- Discovery of exposed sensitive data (e.g., credentials, secrets) that could lead to a security breach if not remediated
Critical
An incident with very high impact on customers, and with the potential to existentially affect the company or reduce revenue.
Examples
- Posthog Cloud is completely down
- A data breach, or loss of data
- Event ingestion totally failing - we are losing events
- Discovery of an active security exploit, such as a compromised user account or system
- Detection of ransomware, malware, or unauthorized modifications to production systems
What happens during an incident?
When an incident is declared, the person who raised the incident is the incident lead. It’s their responsibility to:
- Make sure the right people join the call. This includes the current on-call person (@on-call-global in Slack) and the team responsible for the alert (we have a workflow which will try to add these people automatically). Optionally, add people from Infra and the feature owner and Support. Product Marketers can assist in running communications if required.
- Take notes in the incident channel. This should include timestamps, and is a brain dump of everything that we know, and everything that we are or have tried. This will give us much more of an opportunity to learn from the incident afterwards.
- Update the status page. If the incident happens during business hours, the incident should have a Support TeamSupport Team watcher. Support can help review the messaging for clarity. The status page can be updated from:
- (recommended) the incident Slack channel using
/incident statuspage(/inc sp) - the status page area of the incident.io dashboard (only recommended for corrections/modifications - Slack tooling provides better context)
- (recommended) the incident Slack channel using


The incident lead role is not responsible for fixing the incident, they're responsible for managing it. Sometimes that will be the same person. But if it is too much work for one person, hand over the incident lead role to someone else not actively working on the fix.
Sometimes, customer communication is required. In this case, the incident lead can ask for a comms lead to support the responding team. The best way to do this is to ask for support in the incident channel and use the @all-marketers group tag. Don't be shy.
You can find further production runbooks + specific strategies for debugging outages here (internal)
Force-merging a fix
Occasionally the fastest way to stop the bleeding is to ship a fix that can't wait for the normal review and CI gating. The Force-merge a PR Slack app is the sanctioned break-glass way to do this — it merges a PR even when branch protection would otherwise block it.
This is for exceptional cases only. Take great care, and only reach for it when a fix is genuinely time-critical and waiting on required reviews or checks would prolong customer impact. Any PostHog employee can use it.
To force-merge, open the shortcuts menu in #dev (or start typing /force-) and pick Force-merge a PR, then enter the repo, the PR number or URL, and a reason. Every force-merge is fully audited — it posts to Slack, comments on the PR with who triggered it and why, and is recorded in a tamper-proof log — so be ready to account for it in the post-mortem.
For the full list of guardrails and what the app will refuse to merge, see Break-glass: force-merge a PR.
The PostHog status page
Our status page is the central hub for all incident communication. The Incident Lead owns creating status page updates unless they explicitly hand this over to a Comms Lead. You can update it easily using the /incident statuspage (/inc sp) Slack command.
When updating the status page, make sure to mark the affected component appropriately (for example during an ingestion delay, setting US Cloud 🇺🇸 / Event and Data Ingestion to Degraded Performance). This allows PostHog's UI to gently surface incidents with a "System status" warning on the right. Only users in the affected region will see the warning:
Getting help from a comms lead
Significant incidents such as the app being partially or fully non-operational, as well as ingestion delays of 30 minutes or longer should be clearly communicated to our customers. They should get to know what is going on and what we are doing to resolve it. If the incident is minor this can usually be done by updating the status page, but it may be desirable to do additional customer communications, such as sending an email to impacted customers. When this is required, you should involve a Comms Lead and ensure the Sales team are aware.
The best way to ask for support from a Comms Lead is to post in the incident channel and use the @all-marketers group tag. This will alert the all relevant marketing teams.
When handling a security incident, please align with the incident responder team in the incident Slack channel about public communication of security issues. For example, it may not make sense to immediately communicate an attack publicly, as this could make the attacker aware that we are already investigating. This could it make harder for us to stop this attack for good.
When a customer is causing an incident
In the case that we need to update a specific customer, such as when an individual org is causing an incident, we should let them know as soon as possible. Use the following guidelines to ensure smooth communication:
- Look up the customer's org in Vitally to see if the org has an Account Exec assigned (
PostHog Default Dashboard/ righthand column, scroll down toKey Roles.) If so, let the AE know about the situation early. - Ensure you are always contacting the admins of the impacted organization
- Communication is best done through PostHog Support. It's usually best for the customer's assigned person (check Vitally), or the Support team, to create tickets and handle the communication for you, but don't wait if it's really urgent.
- Before sending any comms, check with the incident lead. Then, share a ticket link in the incident channel.
- If action is needed, it's better to take that action and inform the user than to ask the user to do it.
- If you're not able to take the required action, give the user deadlines for the changes they need to do and explain what will happen if they don't meet the deadline.
- Try to keep all communication on a single ticket, with all relevant parties.
In the case that we need to temporarily limit a specific customer's access to any functionality (e.g. temporarily prevent them from using an endpoint) as a result of certain usage resulting in an incident, we need to make sure that anyone working on a ticket from the org will know what's happening with the org before replying (even if we've already reached out to the org, some folks at the org may not be aware, and so may open a support ticket.)
Post in #team-support with the org name and what's been limited — the support team will make sure tickets from that org are flagged so anyone replying is aware. Once the org's full access has been restored, let #team-support know so the flag can be removed.
When does an incident end?
When we've identified the root cause, implemented a fix, and confirmed all customer-facing services have returned to normal. End the incident by typing /inc close in the incident channel. Make sure to also mark the incident as resolved on the status page.
What happens after an incident?
Once the incident is resolved, the incident lead should step away. Take a walk, go to the gym, have some tea, take a shower. The longer the incident took to resolve, and the more directly customer impacting it was, the more important this is. Bring another team member up to speed, hand off outstanding customer communications, and get your head clear for the post-mortem and followup actions. Anyone else heavily involved in the response should do the same.
In almost all cases, a valid incident will have a post-mortem - check out Post-mortems for more details.