Link a source
Contents
PostHog enables you to link your most important data from sources like your CRM, payment processor, or database. Once linked, you can combine this data with the product analytics data already in PostHog and query across all of it.
To link a source, go to the Integrations tab, and click the Sources tab.
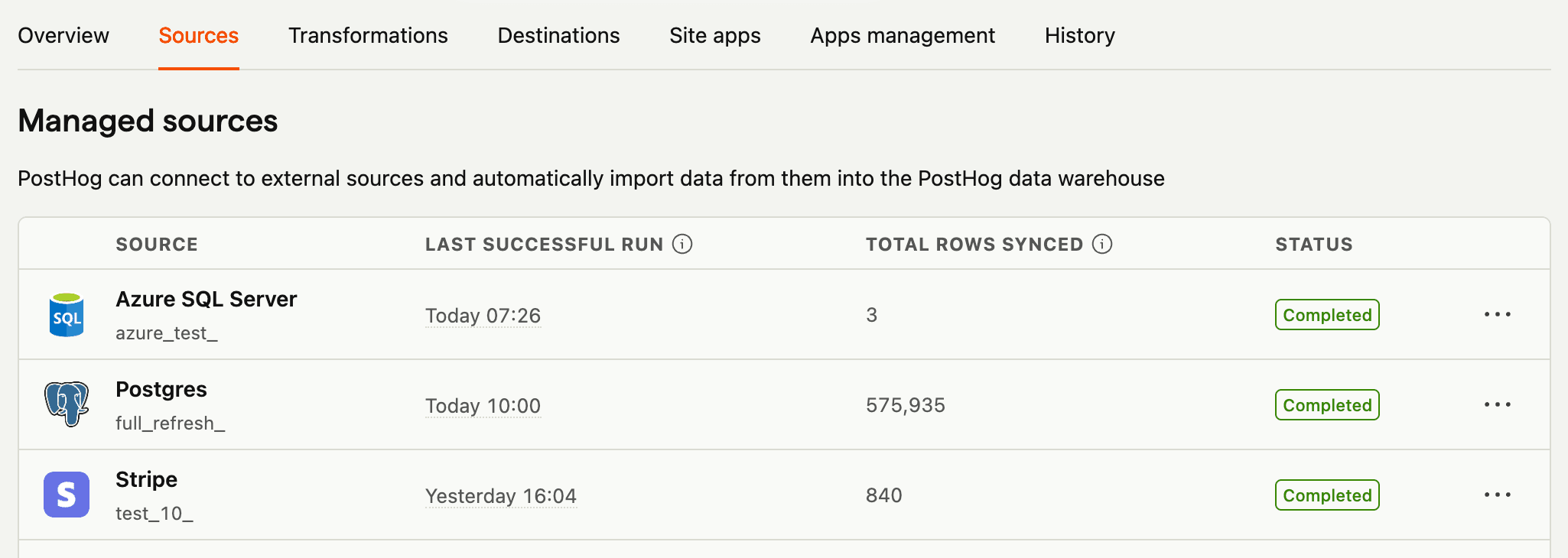
Managed sources
Provide your credentials and PostHog handles the entire extract and load process. Data syncs automatically from your source to PostHog's storage.



















































































































































































































































































































































































































































































































































































































Self-hosted sources
Upload a CSV, JSON, or Parquet file directly to PostHog, or link files in your own object storage (S3, GCS, R2, Azure Blob). PostHog reads directly from storage on every query.




Inbound IP addresses
We use a set of IP addresses to access your instance. To ensure this connector works, add these IPs to your inbound security rules:
| US | EU |
|---|---|
| 44.205.89.55 | 3.75.65.221 |
| 52.4.194.122 | 18.197.246.42 |
| 44.208.188.173 | 3.120.223.253 |
Linking a custom source
The data warehouse can link to data in your object storage system. To do this, you'll need to:
- Create a bucket in your object storage system like S3, GCS, or Cloudflare R2
- Set up an access key and secret
- Add data to the bucket (potentially using a tool like Airbyte, Fivetran, Stitch, or others)
- Link the table in PostHog
See an example in our S3 setup docs.
Sync methods
When setting up a source, you choose a sync method for each table. The available options depend on the source and table. Some sources also support webhook sync for real-time updates.
Webhook
Webhook sync receives data updates directly from the source via webhooks. This provides the fastest data freshness with minimal sync overhead. It's available only on sources that support webhooks (like Stripe) and is shown as the recommended option when available.
The webhook is configured during source setup.
Incremental
With incremental replication, you only sync new or updated data. This reduces the total number of rows synced and how long it takes to sync.
When choosing incremental replication, you must select a field to identify new and updated data. This is often something like an updated_at timestamp, or an autoincrementing ID. Not all fields are suitable to be used to identify new and updated data, and so we only support the following types as replication keys:
integer(includingbigintandsmallint)datetimedatetimestampnumeric(for Snowflake)
The one downside to incremental syncing is that deletions of data won't be synced to your PostHog data warehouse. You need to use full table refreshes for this.
If you select a nullable field as the replication key, any rows where that field is null are skipped during sync. PostHog displays a warning when you select a nullable field. To avoid missing data, use a non-nullable field as the replication key.
Primary key columns
Incremental sync uses primary key columns to deduplicate rows. During source setup, PostHog auto-detects primary keys from your source's metadata (such as INFORMATION_SCHEMA constraints). If no constraint is found, it falls back to an id column when one exists.
For sources like BigQuery views that don't support primary key constraints, or tables with non-standard primary key names (like _id), you can select custom primary key columns during setup. This is available for all managed SQL sources: Postgres, MySQL, MSSQL, Redshift, Snowflake, and BigQuery.
Once the first incremental sync completes, the primary key columns are locked and can't be changed. To modify them, delete the synced data first.
PostHog displays a warning if your selected primary key columns are nullable, since null values can cause deduplication issues.
Lookback window
For timestamp or date incremental fields, you can configure a lookback window to re-read recent data on each sync. This catches late-arriving or backdated rows that would otherwise be missed because the watermark has already advanced past them.
The lookback subtracts time from the stored watermark when querying the source, creating a rolling overlap window. For example, with an 8-day lookback, each sync re-reads the last 8 days of data. The stored watermark continues advancing normally, so you don't lose your place. Incremental sync's merge-by-primary-key makes the re-read idempotent – duplicate rows are deduplicated automatically.
To configure a lookback window, enter a duration (in minutes, hours, or days) when selecting the incremental sync method during source setup or in the schema settings. The maximum lookback is 60 days.
Lookback windows are only available for incremental sync, not append-only sync. They only apply to datetime, date, and timestamp incremental fields – integer or numeric fields aren't supported.
Note: For
dateincremental fields, sub-day lookback values have no effect since date arithmetic only counts whole days.
Append only
Append only does what it says on the tin: append rows to your table.
We use a cursor in the form of an incremental field (similar to incremental syncing above) to query the source for new data. This replication method won't merge any rows, but this can cause duplicate data if you're using an incremental field that can change. To avoid this, we recommend using a timestamp field like created_at.
Append only is ideal for tables where rows are never updated, only added. A common example is an event log table, where each new event is recorded as a new row and existing records remain unchanged.
As with incremental syncing, selecting a nullable field as the cursor skips any rows where that field is null.
Full table
This reloads the whole table on every sync. This is great for tables with common data deletions or ones without an incrementing field (such as a updated_at timestamp).
xmin (Postgres only)
xmin sync uses PostgreSQL's hidden xmin system column as an incremental cursor. Use it when your table has no reliable updated_at or incremental field and you want incremental syncing without setting up CDC.
Requirements:
- PostgreSQL 13 or newer
- Table must have a primary key
- Only regular tables and materialized views (not views, foreign tables, or partitioned parents)
xmin does not capture deletes. If you need delete tracking, use CDC instead. See the Postgres source documentation for more details.
Filtering rows
SQL sources (Postgres, MySQL, MSSQL, Snowflake, BigQuery, and Redshift) and ClickHouse support row filters. Row filters let you control which rows sync from a source table by specifying conditions like created_at > '2024-01-01'. This reduces sync time and storage costs by syncing only the data you need.
Filters are applied as a WHERE clause on the source query, so only matching rows are fetched and synced. Row filters are not available for tables using CDC sync.
Note: Row filters are only available for SQL sources and ClickHouse. API sources (Stripe, HubSpot, Zendesk, Paddle, etc.) do not support row filtering.
Configuring row filters
To add row filters during source setup:
- In the table picker, click Columns next to any table.
- Under Row filters, click Add filter and configure:
- Column - Select the column to filter on
- Operator - Choose a comparison operator
- Value - Enter the filter value
- Add more filters as needed (up to 20 per table). Multiple filters are ANDed together.
You can also add or change row filters after setup:
- Go to the sources tab and click your source.
- Click Configure next to any schema.
- Under Row filters, add, edit, or remove filters.
- Click Save.
Supported operators
| Operator | Description |
|---|---|
> | Greater than |
>= | Greater than or equal |
< | Less than |
<= | Less than or equal |
= | Equals |
!= | Not equal |
IN | Matches one of a comma-separated list of values |
NOT IN | Does not match any of a comma-separated list of values |
Supported column types
Row filters validate values against the column's data type. Columns with unsupported types (like json or jsonb) are not filterable.
| Type category | Example types | Value format |
|---|---|---|
| Integer | int, bigint, smallint | Whole numbers like 100 |
| Numeric | decimal, numeric, float | Decimal numbers like 99.99 |
| String | varchar, text, char | Text like active |
| Boolean | boolean, bool | true or false |
| Date | date | 2024-01-15 |
| Timestamp | datetime, timestamp | 2024-01-15T10:30:00 |
How row filters work
- Filters apply on the next sync — they don't remove rows that have already been synced.
- If a filter references a column that no longer exists or has a type mismatch, the sync fails with an error message. Fix or remove the filter to resume syncing.
- Sampling and row count estimates remain unfiltered.
Syncing
Once you add a source, you can see its status, sync frequency, and last successful run in the sources page. You can also reload or delete sources here.
When you expand each source, you can see:
- Schema name
- Enable or disable syncing for that table
- Synced table name in PostHog
- Time the table was last synced
- Rows synced – the number of rows in the synced table. During an active sync, a spinner and live row count display, updating approximately every 5 seconds. Once complete, the final row count appears. Rows being synced are not queryable until the sync completes.
If you add new tables to your source database, click Pull new schemas to discover them without waiting for the next sync. This only updates the list of available schemas – it doesn't trigger a data sync.
To sync all enabled schemas at once, click Sync all enabled schemas. A confirmation dialog appears before the sync starts. This triggers a new sync for every enabled schema that isn't already syncing, so you don't need to sync schemas one by one.
Filtering and sorting schemas
The schemas table supports filtering and sorting to help you find specific schemas in sources with many tables.
You can filter schemas by:
- Status - Running, Completed, Error, etc.
- Sync method - Incremental, Full table, xmin (Postgres only), CDC, or schemas not yet set up
- Frequency - Filter by a specific sync interval
You can also use the name search and the Show enabled only toggle to narrow results further.
All columns in the schemas table are sortable, including schema name, status, frequency, last synced, and rows synced.
Managing schemas in bulk
Select multiple schemas using the checkboxes in the schemas table to perform bulk actions. The following bulk actions are available:
- Disable - Disable syncing for all selected schemas. A confirmation dialog appears if any selected schemas use CDC or webhook sync, since re-enabling them requires a full resync.
- Set frequency - Change the sync frequency for all selected schemas at once. If the selection includes non-CDC schemas, only frequencies of 5 minutes or longer are available.
- Sync now - Trigger an immediate sync for all selected schemas that are enabled and have a sync method configured. Schemas that are disabled or don't have a sync method set up are skipped.
- Delete tables and resync - Delete the synced data in PostHog and re-import it from scratch.
- Delete tables from PostHog - Remove the synced tables from PostHog without affecting the data in the source.
Bulk enable is not available – you must enable schemas individually since each one requires selecting a sync method and configuration.
Sync frequency
CDC (Change Data Capture) schemas support sync frequencies as low as every 1 minute. All other sync methods (Incremental, Full table, Append only) have a minimum sync frequency of 5 minutes. This restriction is enforced in both the UI and the API.
Anchor time
Anchor time pins the sync schedule so runs start at a predictable time each day. This is useful for coordinating syncs with downstream jobs or reports. Anchor time only applies to sync intervals longer than one hour.
The anchor time is stored in UTC. When your project timezone is something other than UTC, a toggle lets you view and set the anchor time in either UTC or your project timezone.
Managing webhook tables
Webhook-synced tables have special behavior when enabling or disabling them:
Disabling a webhook table - When you turn off syncing for a webhook table, a confirmation dialog warns you that the webhook stops consuming data immediately. Any events sent while the table is disabled are lost.
Re-enabling a webhook table - When you re-enable a previously disabled webhook table, PostHog automatically triggers a full refresh sync. This ensures no data gaps from the period when the webhook was inactive.
Enabling a new webhook table - For sources with provider-side webhook subscriptions (like Stripe), PostHog automatically adds the required events to the webhook when you enable a new table. This requires the appropriate permissions – for example, Write on Webhooks for Stripe restricted API keys, or an OAuth connection. If automatic sync isn't possible (due to missing permissions or a manually created webhook), PostHog shows a warning banner in the Webhook tab listing the events you need to add in your provider's dashboard.