







How YC's biggest startups run A/B tests (with examples)

Contents
A/B testing is powerful when used correctly, but it's easily misused. Only comparing the old version with a new feature, copy change, or query does not create success.
In the wise words of Picasso: "Good artists copy, great artists steal." So, to help you become a great A/B test "artist," we’ve researched how some of Y Combinator’s most successful companies do A/B tests.
If you're new to A/B testing, we recommend reading our software engineer's guide to A/B testing as a primer.
1. Monzo – Low-risk "pellets" > slow-moving "cannonballs"
Monzo, an online banking app, provides a classic example for how to run A/B tests. Monzo's team focus on top-of-funnel tests (because those impact the most users) and run about 4 per month. Most tests are simple page comparisons, but some are holdout tests where 10% of participants continue to see the control variant weeks after the test to ensure no long-term negative effects.
An A/B test at Monzo starts with a proposal anyone can submit. It asks four questions:
- What problem are you trying to solve?
- Why should we solve it?
- How should we solve it? (optional)
- What if this problem didn’t exist? (optional)
These proposals also include data on impact and scale. Data informs success metrics and guardrail metrics to ensure impact and avoid unintended consequences. The goal of the proposal is to create a clear hypothesis containing a solution to a problem or an outcome for an experiment. This needs to be specific, measurable, and testable.
After completing the proposal, experiments launch as small, quick-to-build, low-risk "pellets" rather than large, slow "cannonballs." "Pellet" experiments wrap faster, enabling Monzo to trigger new experiments and retain momentum.

✅ Takeaways:
- Focus on the top-of-funnel for the highest impact.
- Create a consistent process for A/B tests and hypotheses.
- Ship low-risk "pellets," rather than slow-moving "cannonballs."
📖 Further reading:
2. Instacart – Solving a complex sampling problem
Instacart, a grocery delivery service, shows a more complicated example of A/B testing. In this example, Instacart's goal was to increase the efficiency of delivery routing, which followed one of two strategies:
- Handoff: One person preps, while another collects and delivers.
- Full service: One person does everything: prep, collection, and delivery.
For each order, Instacart's routing algorithm tries to create a handoff trip, and if it isn't possible, creates a full service trip. The team wanted to test a new algorithm splitting orders into handoff or full service depending on which was more efficient from the start, rather than successively.
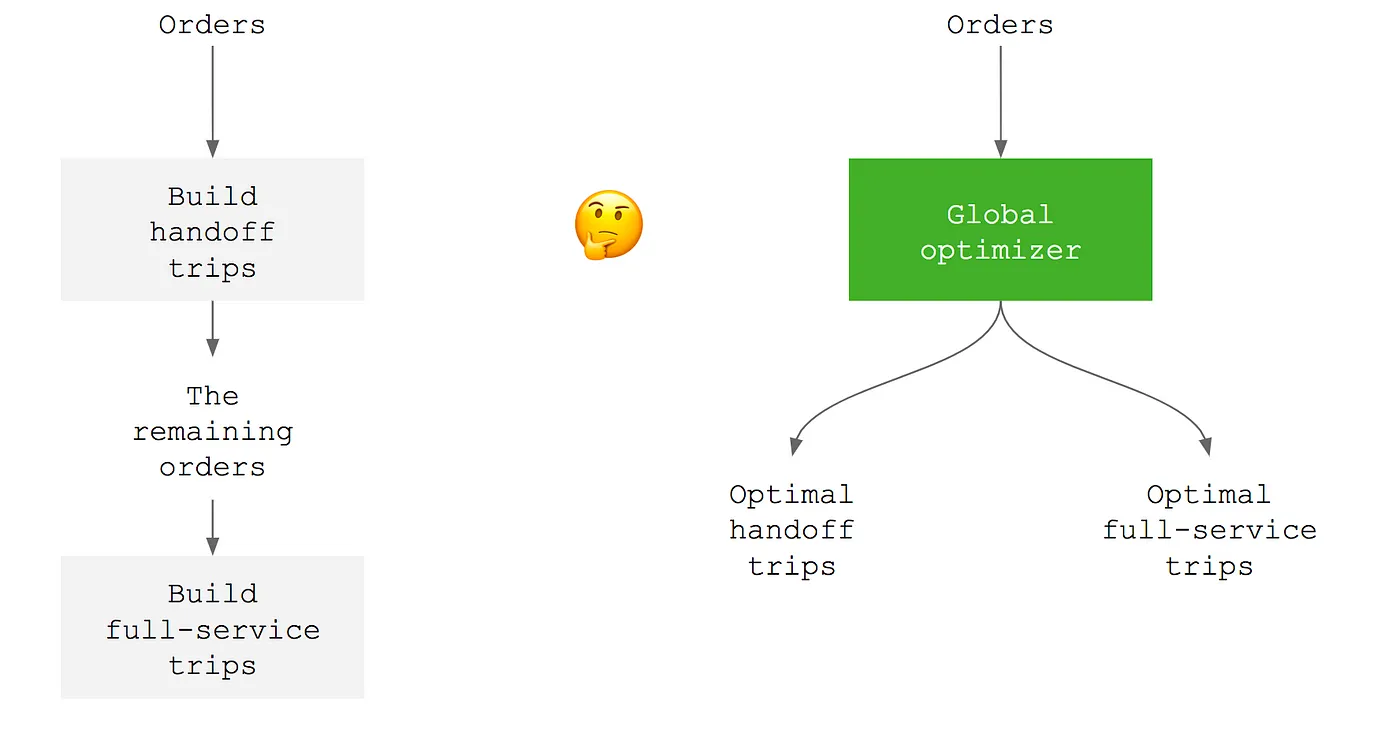
When planning the test, they realized they couldn’t just split by customer or shopper because those were interdependent. For example, deliveries from both algorithms might dispatch to the same shopper. Instead, they experimented and analyzed the new algorithm in three ways:
With Simulations to replay the history of customer and shopper behavior using the new algorithm. This showed a 2.1% increase in efficiency.
After the simulations were positive, they temporarily launched the new algorithm to everyone in San Francisco. Doing before and after analysis showed an estimated efficiency increase of 2.9%.
Along with this, they checked differences in differences to compare SF (where the change launched) and Oakland (where it didn’t) which were geographically similar and showed correlated efficiency before and after the change.
None of these options proved the change caused an improvement, only that changes correlated to improvement. Each analysis also missed potentially impactful variables like geography and time.
To solve this, Instacart's team had to figure out a new way to split samples. They realized since orders happen locally, they don’t have to optimize everywhere at once. They can split by geographical regions (called "zones") and day (because their delivery system "clears" overnight).

Running an A/B test of the new and old algorithms split by zone and day showed an increased average efficiency. A simple regression of the response variable efficiency on the group variable variant showed it. It also showed a p-value was 0.079 which was higher than the 0.05 threshold, meaning it wasn’t significant.
What is a p-value? A p-value is the probability of obtaining a result equal to or more extreme than what was observed assuming the null hypothesis is true. A p-value of 0.05 means that if the null hypothesis is true, there is a 5% chance of observing the data or more extreme results purely due to random chance.
The simple regression left out potentially important variables like zone, day of the week, and week number (growth). To include these, they used multivariate regressions. This showed a similar improvement in efficiency but with a much lower p-value of 0.0003.
With this, Instacart was confident the new algorithm led to improvements in delivery efficiency and rolled it out further.
✅ Takeaways
- Sometimes randomly splitting users into test and control samples won't work, but there is always some way to do it, such as by geography.
- A simple regression doesn’t account for multiple variables, which leads to higher, insignificant p-values. A multivariate regression could provide a more accurate answer.
📖 Further reading:
- It All Depends on the Tech at Instacart blog

Subscribe to our newsletter
build mode
Read by 75,000+ founders and builders
We'll share your email with Substack
3. Coinbase – Scaling tests by separating experiment and functional code
Coinbase had a different challenge from Monzo and Instacart. To improve their machine learning algorithms, Coinbase needed to run a high volume of tests. Because tests impact each other, they needed separation. This created a bottleneck: there weren’t enough separate user samples to run all the tests they wanted.
A potential solution was running many tests simultaneously, but this requires complex reasoning, documentation, and alignment, which is a lot of work. It also introduces invisible and scattered complexity, which is arguably the worst kind.
To support a higher volume of tests, Coinbase developed "universes." This is a system to split users into groups, assign A/B tests to those groups, then build versions of the app containing the tested components. It consisted of three main pieces:
Components: parts of a service you may want to experiment on.
Composer: builds a service using component constructors, testing one of them. Experiments consist of comparing composers, so they tracked analytics at this level.
Composer manager: routes requests to the correct composer based on the user. They split users into groups, named "slots" which get a single experiment. Those who are part of this experiment get the service the composer put together.
A single configuration file defines all three, abstracting the code relevant to the experiment from the actual app. The composer and manager use the configuration file to create a universe for the A/B test, enabling more tests to run simultaneously.
The outcome of building the "universes" system included:
Increased A/B test throughput from 3 experiments in ~6 months before launch to 44 experiments in ~8 months after.
Centralized and cleaner code by splitting experiment and app code as well as using a single configuration file for the experiment. This makes it easier to manage tests.
Greater flexibility and faster feedback through the ability to modify experiments at any time, requiring smaller user samples, and shorter implementation and feedback cycles.
✅ Takeaways
- Running A/B tests at scale requires you to automate, simplify, and standardize the process as much as possible. 2.You can run more experiments faster by separating experiment code from functional code.
📖 Further reading:
4. Airbnb: Interleaving, dynamic p-values
Although Airbnb has many examples of standard A/B testing, we’re going to cover two unorthodox examples: (i) testing search results with interleaving and (ii) improving accuracy with dynamic p-values.
Testing search results with interleaving
The first is how they A/B test their search ranking algorithms. Instead of a user getting all their results from a test or control variant algorithm, they get both through with a framework called interleaving.
Interleaving is a framework for blending results from both variants to get a direct comparison. It works by:
- Taking search results from both variants.
- Combining similar listings.
- Creating a "competitive pair" from dissimilar listings.
- Judging success based on what listing drives more bookings (conversion).

Airbnb’s interleaving framework requires 6% of the traffic of a regular A/B test and 1/3 the running length. This led to a 50x speed up while providing results that are 82% consistent with regular A/B tests.
Improving accuracy with dynamic p-values
Like many companies, Airbnb had questions about how long to run A/B tests. Relying on a p-value requires you to design an experiment with a desired sample and effect size. Another issue with an arbitrary p-value goal is potentially hitting your it early and ending the test prematurely.
In Airbnb’s case, they found a pattern of hitting "significance," and then converging back to neutral in their experiments. This is because users often take a long time to convert, so early conversions have a disproportionate impact in the beginning of an experiment.
For example, they tested changing the max price filter value to $1,000. In it, the test variant had a positive effect and p-value below 0.05 on days 7 and 13; however, as the experiment went on, the p-value increased to 0.4 and the effect became neutral. If they concluded the experiment on day 13, they would ship a change with no long-term positive impact.

To solve this, Airbnb calculated a dynamic p-value curve starting at 0 and then curving up towards 0.05 on day 30 to determine whether an early result is worth investigating. This creates enforced skepticism about early experiment results and helps reduce false positives.
✅ Takeaways
- A/B tests can be set up to compare variants together rather than split using interleaving.
- A static p-value goal may cause you to prematurely end experiments. A custom, dynamic p-value can provide a more accurate threshold.
📖 Further reading: .
5. Convoy – The benefits of bayesian over frequentist testing
A/B testing usually uses a frequentist method, meaning it focuses on probabilities and p-values to decide a winning variant. The problem with this is it can unnecessarily favor the null hypothesis (aka don’t change). If an experiment doesn’t hit the p-value, new changes don’t get shipped.
If your company prefers to ship more changes, even if they are more likely to be insignificant (aka false positives), a Bayesian A/B testing approach might be better. This is what Convoy, an Uber-style app for trucking, uses. The Bayesian approach accepts more small improvements, even if they aren’t significant.
The Bayesian approach:
Compares prior beliefs of potential values for goal metric (like conversion) with beliefs for a new variant.
Using experimental metrics, calculates the probability that one variant’s goal metric is larger than the other.
When the test variant’s goal metric probability difference hits a threshold, select it as a winner.
This requires some statistical math too complicated to do here, but Convoy followed Chris Stucchio’s guide to set it up.
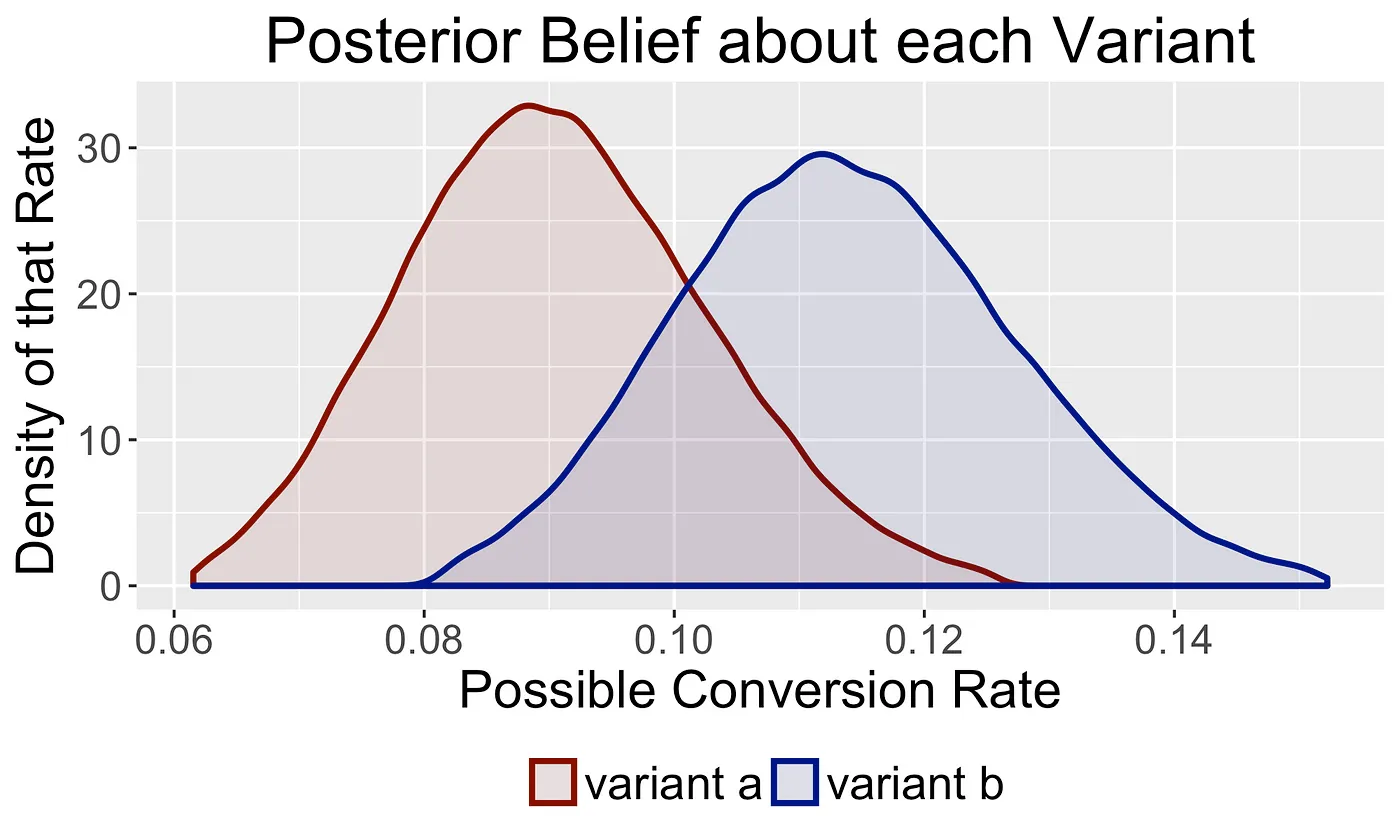
The Bayesian approach focuses more on the average magnitude of wrong decisions over many experiments. This limits making the product worse while maintaining a bias for action. When they stop an experiment, they can be confident they are making a decision that won’t decrease a metric more than a known value, while seeing improvements to the product. By doing this, A/B tests at Convoy can have the highest impact over the long run.
✅ Takeaways
- Standard, "frequentist" A/B test can unhelpfully favor the null hypothesis.
- A Bayesian approach encourages shipping more changes, even if a larger portion of them don’t have a significant impact.
📖 Further reading:
More on A/B testing
- Annoying A/B testing mistakes every engineer should know
- When and how to run group-targeted A/B tests
- Guides to running A/B tests in PostHog
Subscribe to our newsletter
build mode
Read by 75,000+ founders and builders
We'll share your email with Substack
PostHog is the leading platform for building self-driving products. With a full suite of developer tools – AI observability, product analytics, session replay, feature flags, experiments, error tracking, logs, and more – PostHog captures all the context agents need to diagnose problems, uncover opportunities, and ship fixes. A data warehouse and CDP tie it all together, unifying that context into one source agents can read across. You can steer it all from Slack, the web app, the desktop (PostHog Code), or your own editor via the MCP.