





Troubleshooting
Contents
Not yet available to everyone – join the waitlist to get updates.
Common things that go wrong with Replay Vision, and what to do about each.
My scanner isn't producing any observations
Check, in order:
- Is the scanner enabled? Disabled scanners don't sweep. The toggle is on the scanner list and on the scanner detail page.
- Are the filters too narrow? Try removing all filters and see whether observations start showing up. If they do, re-add filters one at a time to find the culprit.
- Is the sampling rate 0%? A common oversight – 0% means every matching session gets skipped.
- Is the quota exhausted? Check the usage meter in the Replay Vision header. A scanner whose background sweep is silenced by the cap will silently produce nothing until quota frees up. See quota and limits.
- Is your project recording sessions at all? Replay Vision only sees sessions Session Replay has captured. No recordings, no observations. See events or recordings aren't coming in.
- Is your organization over a usage limit? If Product analytics or Session replay is over its billing limit, new events or recordings are dropped at ingestion and scanners have nothing usable to scan. See usage limits stop scanning.
- Are all the matched sessions ineligible? If your filters happen to match only very short or no-event sessions, the scanner will produce ineligible observations but no successful ones. See running scanners – ineligible sessions.
A fast way to confirm the scanner itself works: run it on-demand against a recording you know is eligible. If that produces a result, the issue is in the filters, the sampling rate, or the quota – not the scanner config.
I'm getting a lot of ineligible observations
Ineligibles don't cost you quota, but a high ineligibility rate usually means the scanner's filters aren't well-aligned with the kinds of sessions your project actually has. Each reason has a different fix:
| Ineligible reason | Most likely fix |
|---|---|
no_recording | The session ID exists but its replay data is missing or expired. Usually a sign you're scanning sessions older than your replay retention. |
too_short | Add a duration filter (e.g. session_duration > 30) so only sessions long enough to analyze are queued. |
too_inactive | Add an event-presence filter (e.g. require at least one $pageview or $autocapture) so silent sessions are skipped earlier. |
too_long | Add an upper duration filter. |
no_events | Require at least one event, as with too_inactive. If nearly every recent scan is no_events, check whether your organization is over its Product analytics limit – see usage limits stop scanning. |
Once you've added the filter, the ineligibility rate should drop. The Observations tab is the source of truth – check it after the next sweep.
Events or recordings aren't coming in
Replay Vision runs entirely downstream of ingestion: scanners can only scan recordings PostHog actually received, and the model's event context comes from the events captured in those sessions. If either stops flowing, Vision goes quiet without erroring:
- No new recordings: background sweeps find no matching sessions and produce nothing at all.
- Recordings but no events: sessions arrive without event data and every scan is marked ineligible with
no_events.
Billing limits are one cause (see usage limits stop scanning below), but the same symptom appears whenever capture itself stops: session replay is disabled in project settings or in the SDK config, replay capture conditions (sampling, minimum duration) filter out every session, or the snippet/SDK stopped loading after a deploy. Work through the session replay troubleshooting guide to get recordings flowing again.
Vision resumes automatically once new sessions arrive. Sessions that were never captured can't be scanned retroactively, so gaps in ingestion are permanent gaps in observations.
Usage limits stop scanning
Replay Vision depends on two other products' data, so their billing limits affect it even when your Vision quota is fine:
- Over the Product analytics limit: new events are dropped at ingestion. Sessions still get recorded, but they arrive with no event data, so every scan of them is marked ineligible with
no_events. A sudden wall ofno_eventsineligibles is the classic symptom. - Over the Session replay limit: new recordings aren't captured at all, so scanners find nothing new to scan and go quiet.
When either limit is exceeded, a banner appears on the Replay Vision pages linking to your billing settings. Raising the limit (or waiting for the billing period to reset) resumes scanning automatically – no scanner changes needed.
One caveat: sessions from the over-limit window are permanently unscannable. Dropped events and recordings are not retroactively recovered, so those ineligible observations won't succeed later. Scanning picks up with new sessions once ingestion does.
The model is making bad calls
The reasoning + citations on each observation are your debugging tool here. Open three or four observations the scanner got wrong and read them.
Common patterns and fixes:
- The model is guessing intent or emotion from sparse evidence. Rewrite the prompt around observable behavior (rage clicks, repeated retries, time without progress) instead of inferred states (frustrated, confused). See creating scanners – writing the prompt.
- The model is taking a position on ambiguous sessions. Add an explicit "when unsure" branch: "If there isn't enough evidence to tell, answer no" or "tag it
unclear." - A classifier is over-using one tag. Tighten that tag's definition in the vocabulary, or add an
unclear/othertag so the model has somewhere to put marginal cases. - A scorer is bunched up at the extremes. Explicitly anchor the middle of the scale in the prompt: "5 means moderate friction – occasional misclicks but the user eventually progressed."
After each edit, scan a fresh batch of recordings and compare. A recording the scanner has already looked at can't be re-scanned, so iteration always happens on new sessions.
Confidence is always low
A few causes:
- Sessions are too short or too sparse. The model genuinely has little to go on. Tighten the filters to longer / event-rich sessions.
- The prompt is too open-ended. A prompt that asks the model to judge something it can't see (intent, satisfaction, "user happy?") will keep confidence low. Anchor it in observable behavior.
- The model picked a tag from a weak vocabulary. For classifiers, vague tag definitions push the model to hedge. Sharpen the definitions.
Confidence is self-reported, so don't over-index on it as a metric. A scanner that's wrong with confidence 0.95 is still wrong. Use confidence as a filter for downstream automation (e.g. "only alert when confidence > 0.7"), not as a quality bar for the scanner itself.
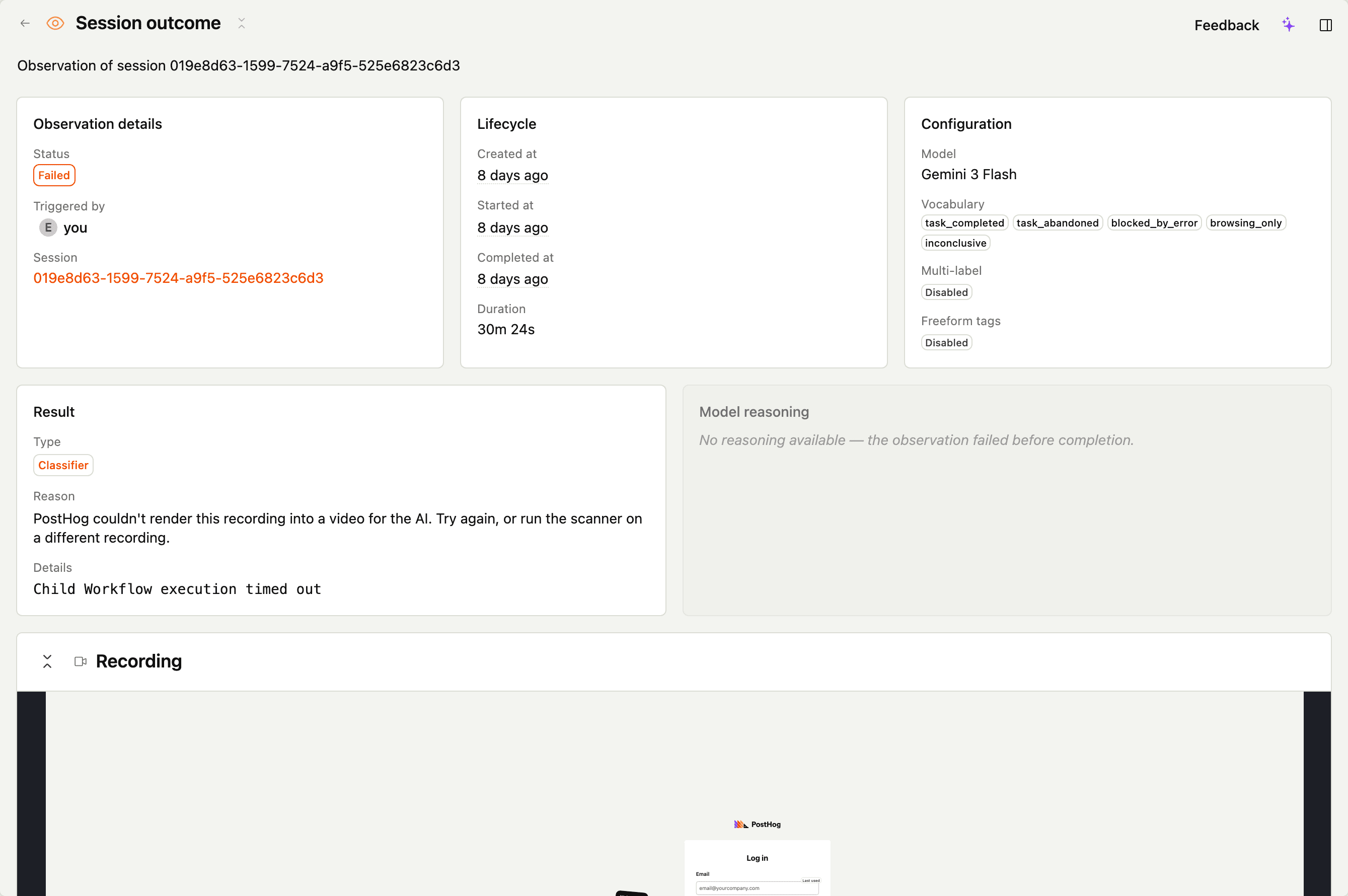
Failed observations
Failed observations show an error reason on the detail page in the form kind:human-readable message.
provider_transient
A transient Gemini error – network hiccup, rate limit, model overloaded.
What to do: a single failure isn't actionable. If you're seeing a burst across many sessions, the upstream model is likely having availability issues – wait it out before triggering more on-demand work.
provider_rejected
Gemini refused to process the input. The most common cause is content policy – e.g. the recording contains material the model declines to analyze.
What to do: narrow the scanner's filters so it doesn't match those sessions in future sweeps.
rasterization_failed
PostHog couldn't render the recording to video. Usually a sign of corrupted snapshot data for that session, or a recording with no usable frames.
What to do: confirm the recording plays in the regular replay player. If it does and rasterization still fails, contact support. If it doesn't play in the regular player either, the underlying recording is the problem – not Replay Vision.
validation_failed
The model returned a response that didn't match the scanner's expected output shape (e.g. a classifier returned a tag not in the vocabulary, or a scorer returned a non-numeric value).
What to do: tighten the prompt to spell out the allowed responses. For classifiers, restate the vocabulary inside the prompt body, not just in the config. For scorers, repeat the scale.
internal_error
Something else went wrong on PostHog's side. These should be rare.
What to do: if you see it more than once, contact support with the observation ID.
Something else
If you're hitting something that doesn't fit the above, reach out – Replay Vision is in beta and the team is actively looking for sharp edges.