





Scanner types
Contents
Not yet available to everyone – join the waitlist to get updates.
The scanner type determines the shape of the structured output the model returns. It's chosen when you create a scanner and can't be changed afterwards – to switch types, create a new scanner.
There are four types:
| Type | What it produces | Use it for |
|---|---|---|
| Monitor | A yes / no verdict, with reasoning | Flagging whether a specific condition occurred |
| Classifier | One or more tags from a vocabulary you define | Bucketing sessions along a dimension |
| Scorer | A numeric score on a scale you define | Rating sessions on a dimension |
| Summarizer | A title and prose summary | Generating a short narrative of what happened |
Every type also returns:
- A confidence score representing how sure the model is about the result – shown as a percentage in the app, stored as a value from 0.0 to 1.0 on the event.
- Reasoning that explains the result in plain language and may include citations – timestamps that link directly to the relevant moment in the recording's timeline. (Summarizers are the exception: the summary itself plays this role, so there's no separate reasoning field.)
The reasoning and citations are the most powerful debugging tool you have for tuning a scanner. If the model is making bad calls, the reasoning shows you why.
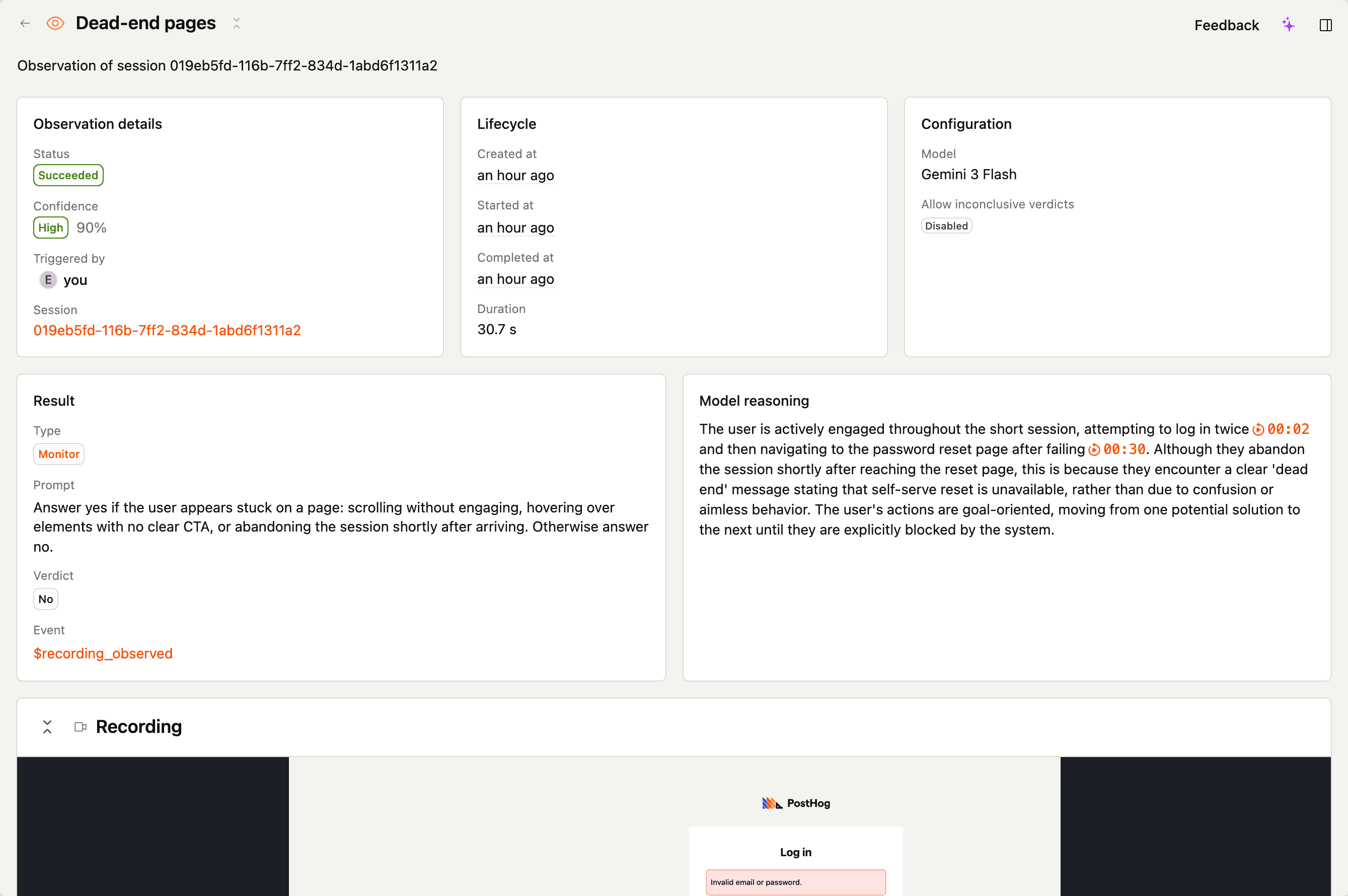
Monitor
A monitor returns a yes/no verdict for whether the condition in your prompt occurred in the session.
Output
verdict–yesorno(orinconclusiveif you opt the scanner into it)reasoning– plain-language explanation, with inline citationsconfidence– how sure the model is
Type-specific config
- Allow inconclusive – whether the model can return
inconclusivewhen it genuinely can't tell from the recording. Off by default; turn it on if you'd rather have an explicit "don't know" than push the model into a forced yes/no.
When to use it
- "Did the user appear stuck on a page?"
- "Did the user trigger a billing-related error?"
- "Did the user complete the onboarding flow?"
Example prompt
Answer yes if the user appears stuck on a page: scrolling without engaging, hovering over elements with no clear CTA, or abandoning the session shortly after arriving. Otherwise answer no.
On $recording_observed – scanner_output_verdict is the string "yes", "no", or "inconclusive". See observations.
Impact and cohorts
Monitors track how many sessions and users matched the verdict-yes condition over a trailing window (default 30 days). The scanner overview shows these impact counts, and you can save the affected users as a static cohort with one click.
The cohort is a snapshot at creation time and doesn't live-update. Use it anywhere cohorts work: funnel breakdowns, retention analysis, survey targeting, or experiment exclusion.
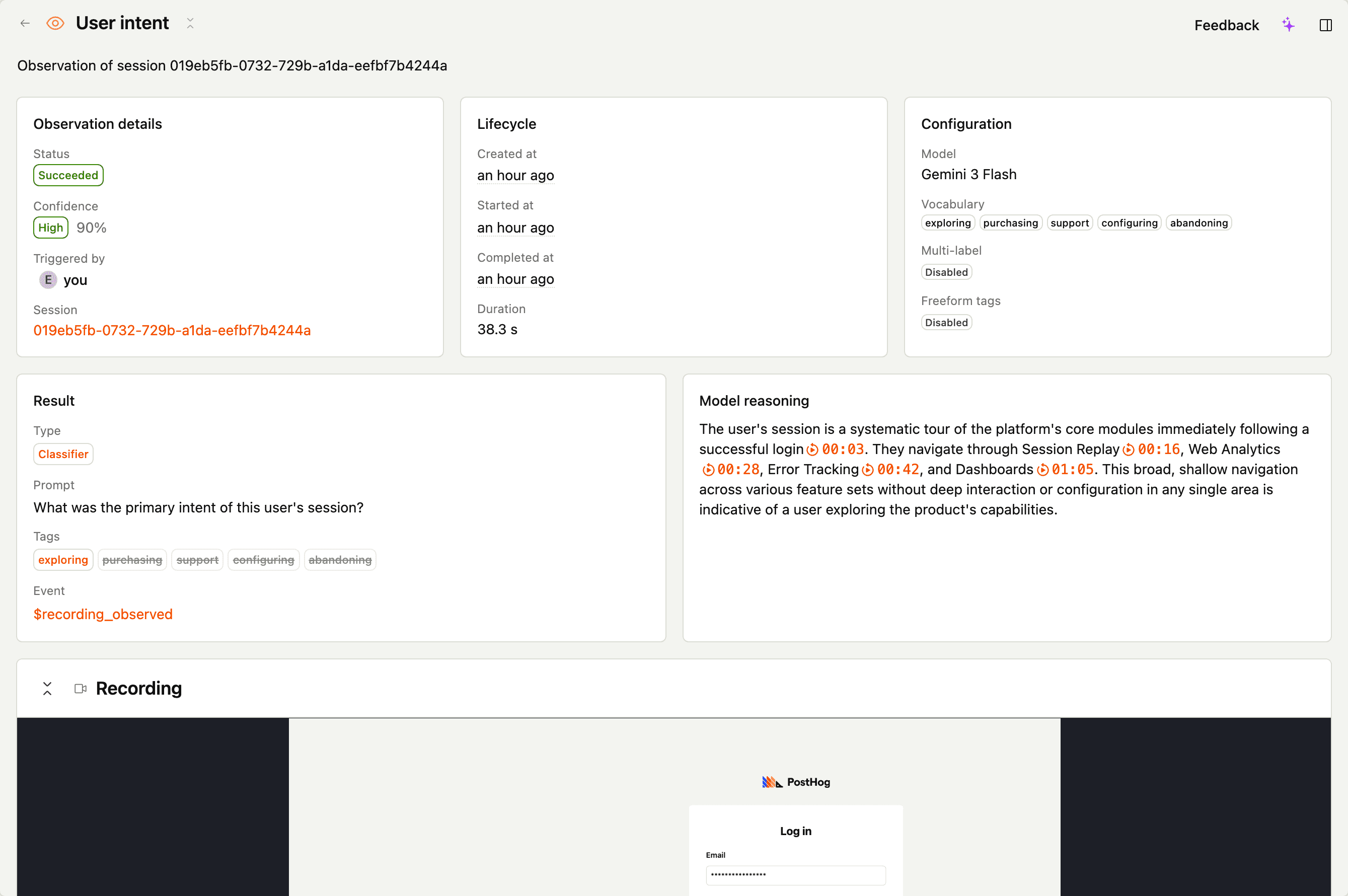
Classifier
A classifier assigns one or more tags from a vocabulary you define. You can also allow the model to invent new tags if your vocabulary is incomplete.
Output
tags– array of tag strings the model pickedreasoning– why these tagsconfidence– how sure the model is
Type-specific config
- Tag vocabulary – the set of allowed tag names. The vocabulary itself is just names – put a short definition of each tag in the prompt so the model knows what it means (see the example below).
- Allow multiple tags – whether the model can pick more than one per session.
- Allow freeform tags – whether the model can invent new tags outside the vocabulary.
When to use it
- User intent:
browsing,purchasing,support_seeking - Session outcome:
task_completed,task_abandoned,blocked_by_error - Page archetype:
landing,product_detail,checkout,account
Example prompt + vocabulary
Tag this session with the user's intent. Pick the single best fit from the vocabulary. Don't speculate – if you can't tell, pick
unclear.
browsing– exploring without a specific goalpurchasing– actively trying to buy somethingsupport_seeking– looking for help, docs, or a contact channelunclear– not enough signal to decide
On $recording_observed – scanner_output_tags is the array of vocabulary tags. Freeform tags, when allowed, land separately in scanner_output_tags_freeform.
Impact and cohorts
Classifiers track impact per tag: how many sessions and users were assigned each tag in the trailing window. Each tag panel in the scanner overview has a button to save that tag's affected users as a static cohort.
The cohort is a snapshot at creation time and doesn't live-update. Use it anywhere cohorts work: funnel breakdowns, retention analysis, survey targeting, or experiment exclusion.
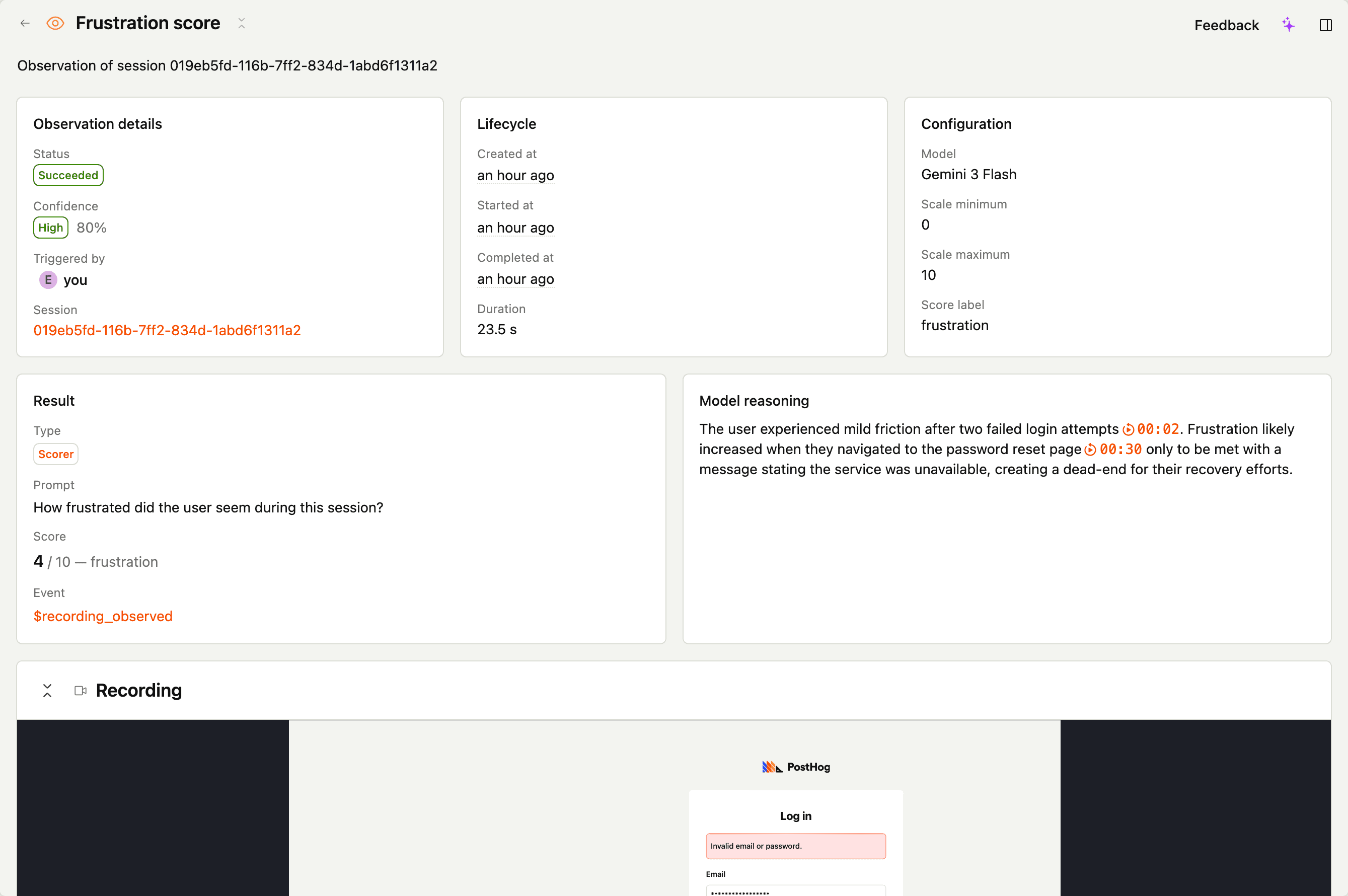
Scorer
A scorer assigns a numeric score on a scale you define – e.g. 0 to 10 for frustration, or 1 to 5 for clarity. Use it when "how much" matters and a yes/no verdict would lose information.
Output
score– numeric value on the scale you definedreasoning– why this scoreconfidence– how sure the model is
Type-specific config
- Scale – minimum and maximum values (integers).
- Scale label – optional short description of what the scale represents (e.g. "0 = no friction, 10 = severe friction").
When to use it
- Frustration / friction level
- Likelihood of completing a goal
- Severity of an error encountered
Example prompt
Score this session 0 to 10 for how frustrated the user appeared, based on signals like rage clicks, repeated retries of the same action, hovering with no progress, and time spent on dead-end pages. 0 means no visible frustration, 10 means severe and sustained frustration.
On $recording_observed – scanner_output_score is the numeric score. Histograms and percentiles over this field tend to be the most useful insights.
Note: Impact tracking for scorers is not yet available in the UI. The API supports querying affected sessions by score threshold via
min_scoreandmax_scoreparameters.
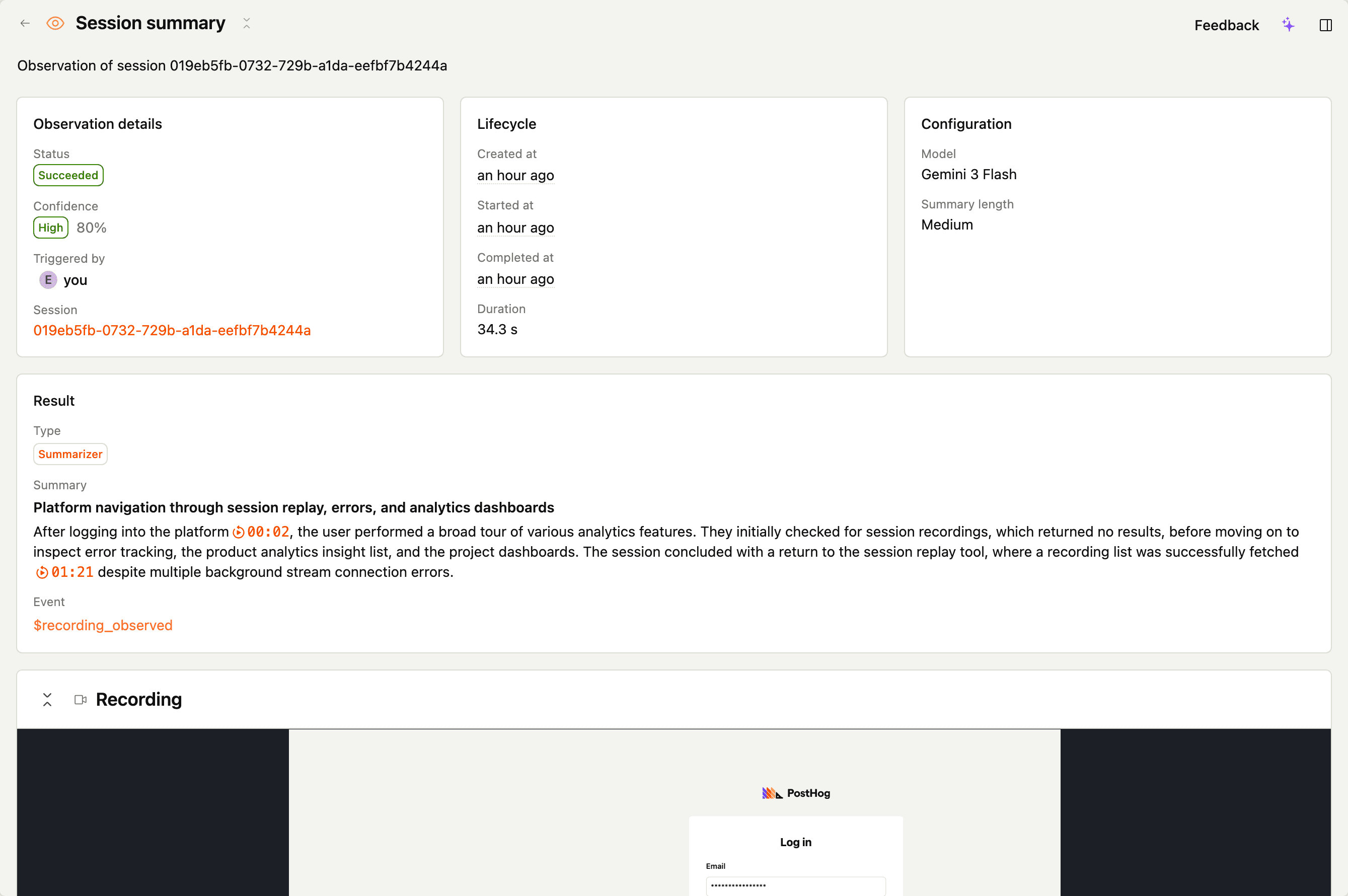
Summarizer
A summarizer produces a short prose summary of what happened in the session, plus a title. Think of it as a TL;DR you can drop into a dashboard or feed to another tool.
Output
title– one-line summarysummary– longer narrative summary, with inline citationsintent– one sentence on what the user set out to dooutcome– one sentence on how the session endedfriction_points– named blockers or frustrations the user hit (empty if none)keywords– distinctive lowercase terms describing the session, for free-text searchconfidence– how sure the model is
Type-specific config
- Summary length – short, medium, or long. Controls roughly how many sentences the model writes.
When to use it
- Daily digest of high-signal sessions
- Triage queues where humans need a one-line preview before clicking in
- Feeding into a downstream analytics or retrieval pipeline
Example prompt
Summarize what the user did in this session: which pages they visited, what they tried to accomplish, and any notable moments like errors, confusion, or successful completions. Be concrete and don't speculate.
On $recording_observed – scanner_output_title and scanner_output_summary carry the title and summary; the facets land as scanner_output_intent, scanner_output_outcome, scanner_output_friction_points, and scanner_output_keywords. See observations.
Note: Summarizers don't support impact tracking or cohort creation since they produce narrative summaries rather than categorical findings.
Picking a type
Some heuristics:
- Binary yes/no? Monitor.
- A small fixed set of buckets? Classifier.
- A magnitude or "how much"? Scorer.
- Don't know what you're looking for yet, but want to skim? Summarizer.
If you find yourself encoding a number range as classifier tags ("low / medium / high"), use a scorer instead and bucket downstream in SQL.
Confidence and citations
Confidence is the model's self-reported certainty. It's useful as a filter (e.g. "only alert when confidence > 0.7") but not as ground truth – treat it as a signal, not a guarantee.
Citations are emitted inline in the model's free-text output (the reasoning field for monitors, classifiers, and scorers; the summary field for summarizers) and rendered as clickable links in the observation detail view. They jump the embedded player to the timestamp the model points at. They're the single best tool for understanding why a model returned what it did.