





Creating scanners
Contents
Not yet available to everyone – join the waitlist to get updates.
A scanner is made up of five things you author:
- A prompt describing what to look for.
- A scanner type that determines the output shape – see scanner types.
- Recording filters that select which sessions the scanner applies to.
- A session coverage mode that pre-filters by recording quality.
- A sampling rate that controls how many matching sessions get scanned.
Start from a template
When you click New scanner you land on the templates picker. The built-in templates cover the most common shapes and are a useful starting point even when your real scanner ends up looking quite different.
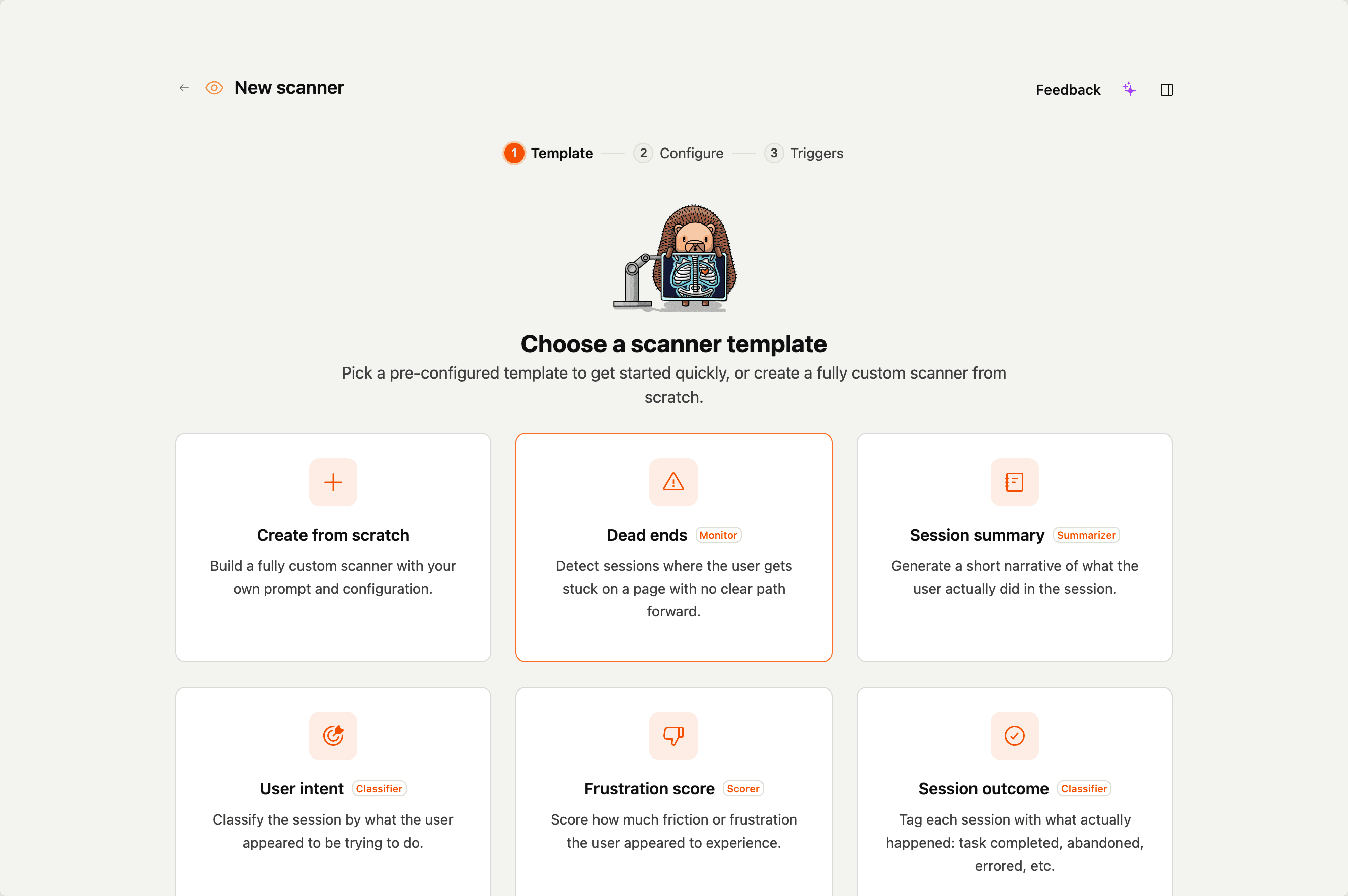
The shipping templates are:
| Template | Type | What it does |
|---|---|---|
| Dead ends | Monitor | Flag sessions where the user appears stuck with no obvious next action |
| Session summary | Summarizer | Short narrative of what the user did |
| User intent | Classifier | Tag each session with the likely intent (browsing, purchasing, support…) |
| Frustration score | Scorer | Numeric score for how frustrated the user appeared |
| Session outcome | Classifier | Tag what happened: task completed, abandoned, errored, etc. |
| Create from scratch | – | Blank scanner – pick a type yourself |
Picking a template just pre-fills the form. You can change anything before saving.
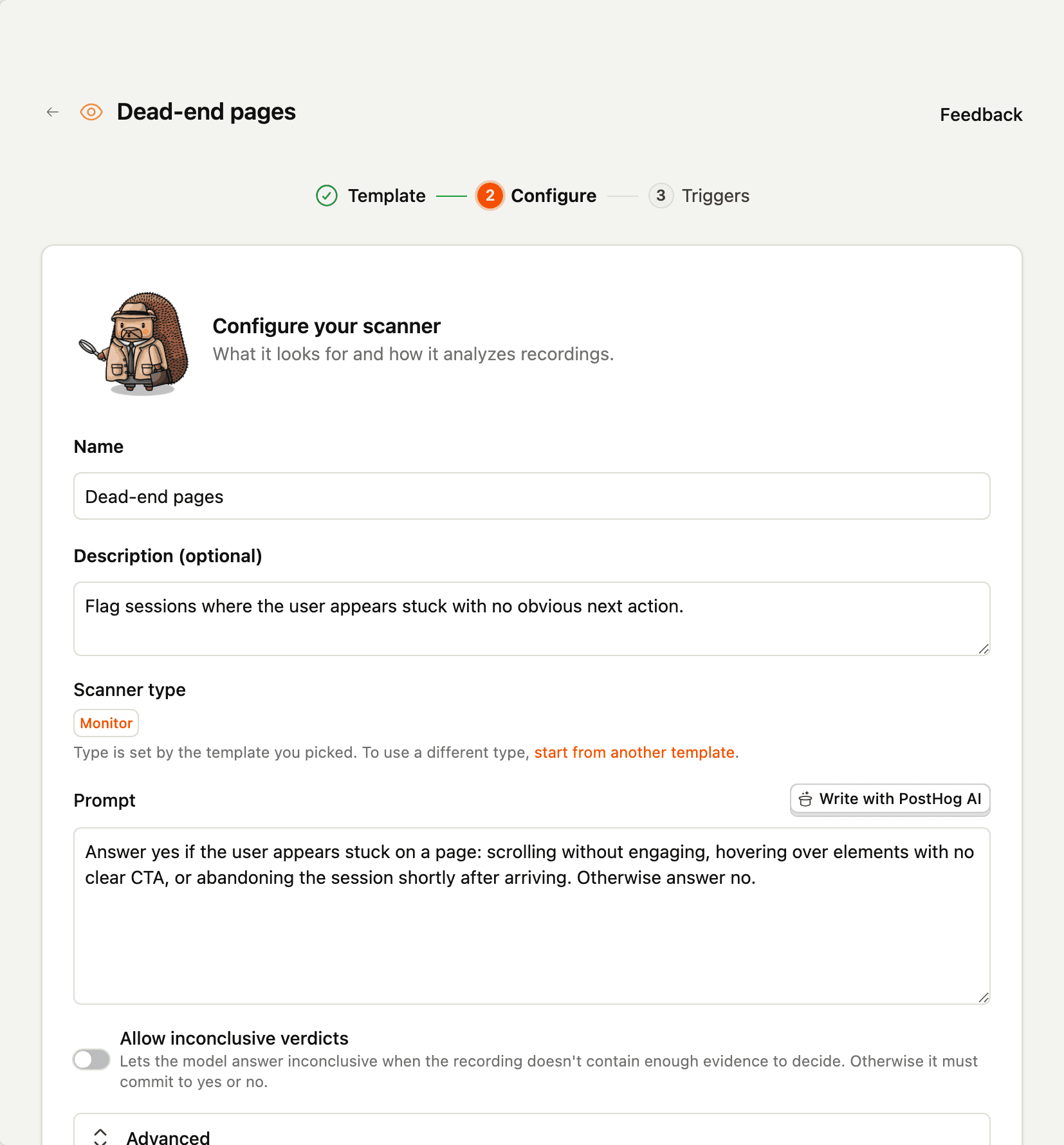
Writing the prompt
This is the single most important thing you'll do. A good prompt is concrete, narrow, and tells the model what to do when it's unsure.
Be concrete, not speculative
The model is good at describing what it sees. It's much less good at guessing intent or emotion from sparse evidence. Anchor the prompt in observable behavior.
✅ "Answer yes if the user scrolls a page for more than 10 seconds without clicking anything and then leaves."
❌ "Answer yes if the user feels confused."
Confusion isn't observable; rage clicks, repeated retries, and dead-end navigation are. Spell those out.
Tell it how to handle uncertainty
When the model is handed an ambiguous session, its default is to make something up. Preempt that by writing the uncertain branch into the prompt.
✅ "If there isn't enough evidence to tell, answer no."
✅ "If the session is too short to judge, tag it unclear."
Cite specific moments in reasoning
Ask for citations in the reasoning, so the result is auditable. The model is already prompted to do this, but it helps to remind it when results are vague.
✅ "Explain your verdict and cite the specific moments in the recording that drove it."
Tune iteratively against real recordings
A prompt that reads beautifully on its own can still misfire. The fastest feedback loop:
- Author the scanner.
- Run it on-demand against 5–10 recordings you already understand.
- Open the observations and read the reasoning + citations.
- Adjust the prompt where the model misread something obvious.
- Scan another batch of recordings and repeat until the results look right.
Hold off on the automatic background sweep until you trust the scanner's on-demand results – every sweep observation counts against your monthly quota, and a poorly tuned scanner can burn through it fast on results you'd throw away anyway.
Drafting prompts with PostHog AI
Inside the scanner editor, you can ask PostHog AI to draft a prompt by describing what you want in natural language. It picks a scanner type, drafts the prompt, and fills it into the form for you to edit.
Type-specific configuration
Each scanner type has a few extra knobs. The full reference is on the scanner types page; the highlights:
- Classifier – define your tag vocabulary, choose whether multiple tags per session are allowed, and whether the model can invent tags outside the vocabulary.
- Scorer – set the numeric scale (min, max) and an optional label describing what the scale means.
- Summarizer – pick a summary length (short / medium / long).
- Monitor – choose whether the model can return
inconclusiverather than forcing a yes/no answer.
Filters: scoping the scanner
Recording filters use the same query builder as the rest of Session Replay. You can filter by:
- Person properties (e.g. plan tier, signup date)
- Session properties (duration, page count, country)
- Cohorts
- Events the session contains
A scanner with no filters matches every eligible session in your project. A scanner with narrow filters – e.g. "sessions on /checkout longer than 30 seconds for users on the trial plan" – is much cheaper, much faster to iterate on, and usually more useful.
A good default discipline: start with a narrow filter while you're tuning the prompt, then widen the filter once you trust the results.
Session coverage: filtering by quality
The Session coverage toggle pre-filters recordings by their predicted quality before sampling is applied. It uses an internally-computed surfacing score that estimates how much meaningful activity a recording contains – engagement, errors, navigation – versus idle or empty sessions.
| Mode | What it keeps |
|---|---|
| Focused | Roughly the top 25% of sessions by quality score |
| Balanced | Roughly the top 65% of sessions by quality score |
| Comprehensive | All sessions – no quality filtering (default) |
Sessions without a score are skipped by Focused and Balanced modes.
The three-step filtering process is:
- Recording filters pick sessions matching your criteria.
- Session coverage drops low-quality sessions by surfacing score.
- Sampling rate randomly keeps a fraction of what's left.
Existing scanners default to Comprehensive, so they behave the same as before.
Use a tighter coverage mode when you want to spend your observation budget on sessions where something actually happened, rather than idle or empty recordings.
Sampling rate: controlling volume
The sampling rate (0–100%) is applied after the filters match. A scanner with filter "sessions over 30 seconds" and sampling 25% scans roughly one in four of those sessions.
The scanner editor shows a per-month estimate of how many observations the scanner will produce, based on your project's recent recording volume, the filters you've set, the session coverage mode, and the sampling rate. Use this to size the scanner against your quota before saving.
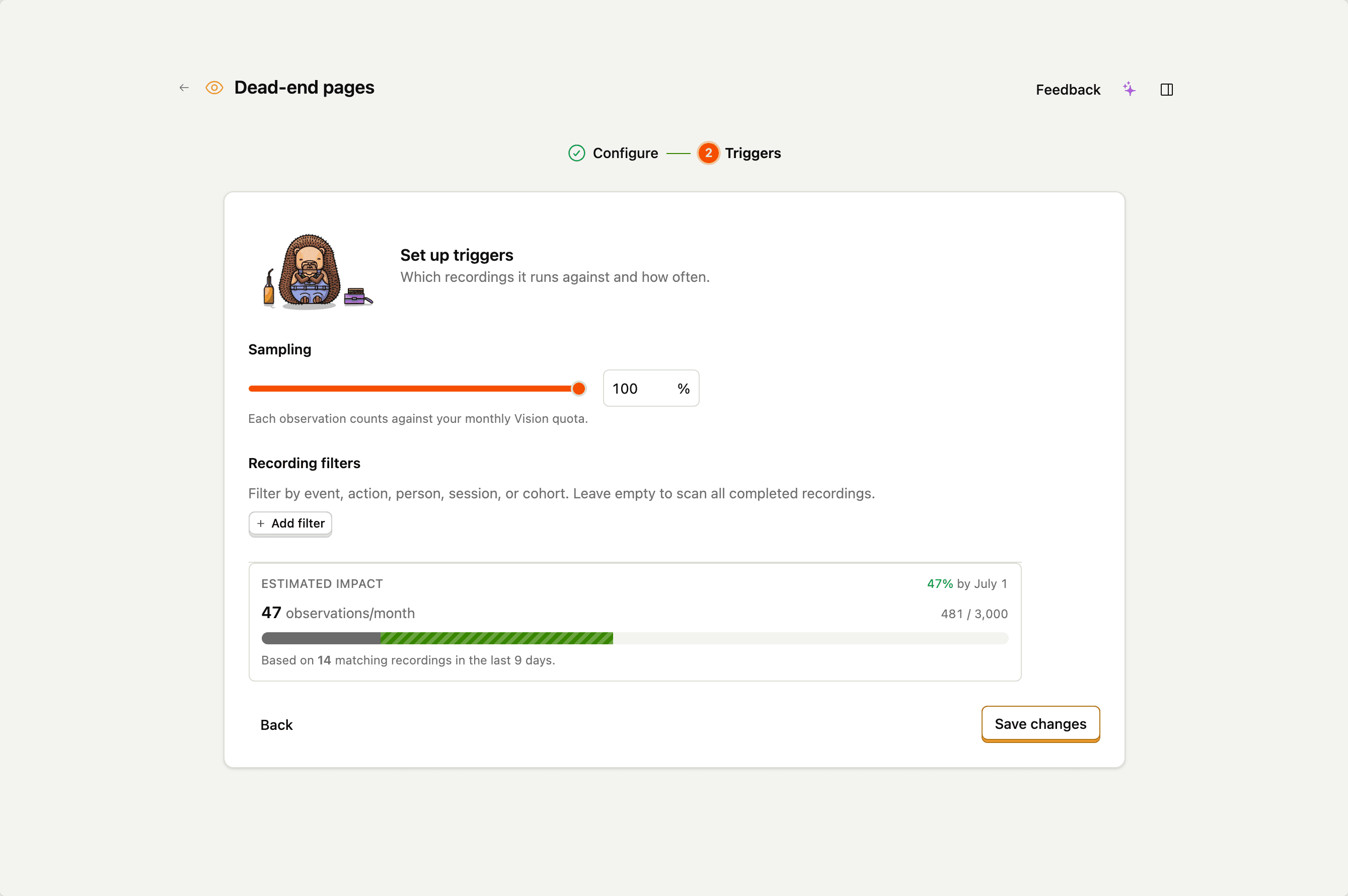
If the estimate looks too high, you have three knobs:
- Narrow the filters.
- Tighten the session coverage mode (Comprehensive → Balanced → Focused).
- Lower the sampling rate.
Enabling and disabling
Scanners are enabled by default when you save. Once enabled, a scanner sweeps for new matching sessions every few minutes.
Toggling a scanner to disabled stops the background sweep. On-demand triggers (from the player or via MCP) still work on a disabled scanner – disabling only affects the automatic schedule.
To stop a scanner entirely, delete it. Deleting a scanner also removes all of its observations from the Observations tab. The $recording_observed events the scanner produced are ordinary PostHog events in your project's event stream and aren't affected – they stay queryable.
Handing off to Responder agents
Each scanner has a Hand off to Responder agents toggle in the configuration step. When enabled, the scanner gains a side mission: during each scan, the model looks for clear, actionable product issues – bugs, broken or confusing flows, errors, or significant UX friction – and reports them as findings.
The scanner's primary task (monitoring, classifying, scoring, or summarizing) is unaffected. The side mission runs alongside it, and most scans produce no finding at all. The bar is deliberately high: a finding must be self-contained and concrete enough for someone with no session context to act on it.
Findings are emitted as signals to the self-driving inbox, where Responder agents can pick them up, research the issue against your codebase and product data, and potentially open a PR.
The toggle is the only setup required – there's no additional configuration in PostHog Desktop Inbox for this source.