







DuckDB vs ClickHouse: Why we use both at PostHog
Contents
ClickHouse and DuckDB are two heavyweights in the OLAP category. This makes them appear as direct competitors. In a few respects they are, but they are essentially tangential products that have garnered popularity in the OLAP world for separate reasons.
In fact, at PostHog, we use both ClickHouse and DuckDB. Today, we want to dissect their precise differences and discuss why an organization like us has appetite for double (OLAP) trouble.
Previously, I'd likened the debate between ClickHouse and Postgres to that of grapefruits and grapes. While the difference between ClickHouse and DuckDB isn't as drastic, it's similar to comparing onions and spring onions: they share a lot in common, but are used for fundamentally different things.
To provide a high-level "say less" tl;dr (or whatever kids say these days): ClickHouse is a feature-packed, highly-configurable database for fast analytical queries on massive data scaled across multiple instances. DuckDB, meanwhile, is an embeddable, single-node engine that shines in two modes: as a query engine for fast exploratory analytics directly over files (CSVs, Parquet, etc.) or as the "SQLite of OLAP", a lightweight analytical database for datasets that can fit on a single machine.
DuckDB has two modes
Comparing products against DuckDB can be a bit disorienting since DuckDB is used in two distinct ways. At its core, it's a lightweight OLAP system. However, how it's used alters how it can scale.
The more lightweight way of using DuckDB is just as a query engine. It is imported, pointed to a local or remote data file, and queried with SQL. That's it. DuckDB will just use memory to organize and store information ephemerally. With this implementation, DuckDB feels more like an API than a complete database.
The more involved way of using DuckDB is as a database, where a persistent .duckdb database file is provisioned. In this scenario, DuckDB creates tables, views, and schemas in the database file that could be reused in future sessions. This is sometimes referred to as an "in process" database. It's similar to how a .sqlite file would work. DuckDB is still mostly a query engine, but this way, it's also managing a consolidated database file.
Because ClickHouse is a complete database, we'll mostly compare the latter database version of DuckDB to it.
ClickHouse is massive (literally)
ClickHouse is a dedicated server for handling and returning analytical data. It is a long-lived process that scales horizontally across nodes with self-managed storage. It is incredibly fast when fine-tuned, made possible by its materialized views, mature compression, and sparse primary indexes. It's fantastic at parallelization and is designed for scaling analytical data across multiple servers.
When new data is ingested, ClickHouse materialized views transform and route incoming rows into destination tables at insert time, following an append-only write model. In the background, the MergeTree engine merges data parts across sharded servers to optimize storage and query performance. This system makes it ideal for our use case, application analytics: as data streams in, it gets absorbed into MergeTrees that translate into near-real-time metrics in PostHog.
DuckDB is lightweight
Even when used as a database, DuckDB is not a server. It functions like SQLite: an embedded, in-process engine that runs as an application. This makes DuckDB easy to spin up, query on local data (including Parquet, CSV, and JSON files) or data anywhere, and spin down. It's ephemeral, single-user, and saves metadata to a portable .duckdb database file.

ClickHouse is typically faster than DuckDB at heavy, optimized queries given its massive toolset to optimize retrieval and pre-calculate aggregates; however, DuckDB is fantastic at spontaneous, smaller analytical queries as it skips client-server communication and operates on local data in a stock setup. For many users, data is just ingested once, queried, and then the DuckDB instance is destroyed.
Notable ClickHouse and DuckDB libraries
There are two other ClickHouse and DuckDB libraries that lend to their flexibility: clickhouse-local and DuckLake. To provide a holistic picture of both ecosystems, we'd like to acknowledge these.
What is clickhouse-local?
Just like how DuckDB has a lightweight (query engine) and heavyweight (database) implementation, ClickHouse also has variations.
clickhouse-local is a portable distribution of ClickHouse that's embedded without a full database server. In many ways, it's the DuckDB version of ClickHouse, as it can index Parquet files and has been benchmarked against DuckDB.
However, by ClickHouse's own position, clickhouse-local was not designed for serving end users or applications. It's more of a portable tool for testing queries and one-off data processing than something designed to serve production applications or scale horizontally. So, for the rest of this piece, we'll stick to the production-grade ClickHouse build.
What is DuckLake?
DuckLake is a data lake built by the DuckDB team. For those unfamiliar, data lakes store raw, unstructured data side-by-side with structured data for future querying. DuckLake provides this flexibility with a native integration with DuckDB. Unlike DuckDB, DuckLake isn't subject to the same single machine sizing constraints as DuckDB and can be used for durable, massive storage for datasets intended for DuckDB queries.
Infrastructure match-up: scaling ClickHouse versus DuckDB
For our first major match-up, let's zoom into the infrastructure differences between ClickHouse and DuckDB as it highlights their very different designs. Obviously, there's some configuration variability, but for the sake of comparison, we'll assume a quintessential version of both: ClickHouse being implemented for its massive scalability and batteries-included tooling, and DuckDB being used for its portability.
ClickHouse scales both vertically and horizontally. That means that a single ClickHouse instance can scale up, using more RAM, CPUs, and storage (vertical scaling), but could also spread across multiple machines, splitting data and routing queries. When horizontally scaling, ClickHouse users typically implement a shared-nothing approach in self-managed deployments, where data is sharded across multiple instances with no overlap.
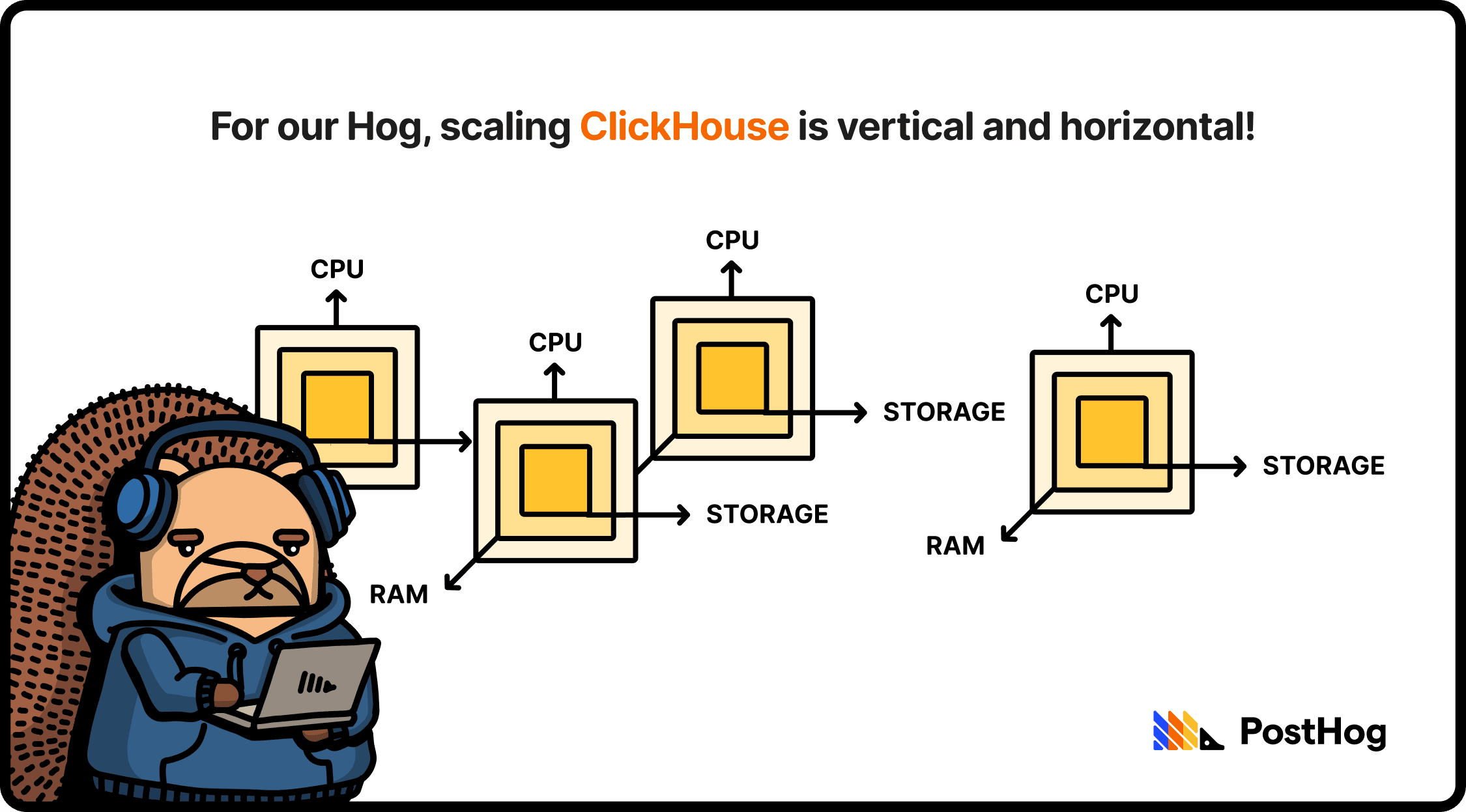
DuckDB is just a single process that scales vertically, all embedded in a single file. When you run out of resources, you'll need to bump up the instance or migrate DuckDB to a beefier server.

This also means that DuckDB evades the complexities of horizontally scaling. ClickHouse (via Apache ZooKeeper or ClickHouse Keeper) has to track every data part, every merge, and every insert across every replica. That's a challenge when dealing with thousands of tables and millions of ingested events. To address this, some developers prefer ClickHouse's paid offering, ClickHouse Cloud, which stores data in object storage (e.g. S3), treating compute nodes as stateless workers with a cache.
A challenge with scaling DuckDB as an embedded database is the compute-storage coupling issue, where pre-spec'd servers might only ship with compute and storage coupled, leading to one of the two resources being over-provisioned. However, this isn't the case when using DuckDB as a query engine. For PostHog, we provision independent servers for each DuckDB process, but point it to an independent storage unit (specifically, DuckLake with a Postgres catalog).
Interface match-up: connecting to ClickHouse versus DuckDB
A second point of difference is how you interface with ClickHouse and DuckDB.
Because DuckDB is embedded, it is queried on-device. Of course, it might be accessed via an SSL tunnel or a proxied service (e.g. Duckgres), but its base implementation involves no server-client relationship. Just an import statement, a SQL query, and that's it. It reads and writes local files natively and integrates tightly with Pandas/Polars DataFrames. A single DuckDB file can be opened by one read-write process or many read-only processes (but not both simultaneously).
When using DuckDB as an embedded engine, you also have the independence of a simple import statement and SQL query. The files might be accessible via network (e.g. stored in a data warehouse or S3 bucket).
ClickHouse, meanwhile, is a server. That means interfacing with it over HTTP or a native TCP protocol. Additionally, because ClickHouse has a native client-server interface, it sports first-party features like authentication and connection management. It also supports multiple concurrent writers and readers, made possible by being a multi-threaded server process.
For ingestion, the databases also differ. For DuckDB, files are typically loaded in batches, tracked by the .duckdb database file. For ClickHouse, conversely, events tend to be streamed in continuously, progressively added via the MergeTree engine.
Despite their interface differences, both databases speak a SQL variant. The ClickHouse variant has some non-standard syntax like array functions, the FINAL keyword for deduplication, etc. DuckDB's variant is closer to stock Postgres, but with some nice additions like EXCLUDE, COLUMNS(*) regex matching, and direct file-path-as-table-name queries.
Performance match-up: measuring ClickHouse and DuckDB
Comparing ClickHouse and DuckDB on performance is tricky. On small-to-moderate datasets, DuckDB can match or beat ClickHouse on cold queries since it avoids network overhead and has an efficient vectorized engine. But on large datasets with tuned materialized views and indexes, ClickHouse will always pull ahead.
This is a bit of a flawed comparison, however. The purpose of ClickHouse is to serve long-standing queries. It's a heavily tunable database. For example, PostHog might run a ClickHouse query that aggregates all of the views of the database to establish the average time spent per session — it's the same query that could be pre-empted by materialized views. DuckDB, meanwhile, is designed to serve ad hoc queries at blazing-fast speed with minimal set-up.
Type match-up: how ClickHouse and DuckDB structure data
ClickHouse's entire data system is built around its MergeTree family. It has specific MergeTree variants like ReplacingMergeTree, AggregatingMergeTree, or SummingMergeTree that are optimized for specific insertion or mutation patterns. Developers choose a variant, a sorting key, and a partition scheme that tunes to the use case. It's complex, but incredibly efficient at scale.
DuckDB is the opposite. It's super flexible, supporting nested and semi-structured data natively, such as structs, lists, maps, and unions. It's optimized for developer experience, not sub-millisecond-minimizing-readiness. With DuckDB, you can query a nested JSON or Parquet file in S3 without flattening it. It's the Swiss army knife OLAP database.
How we use ClickHouse and DuckDB (and Postgres)
PostHog uses three databases. For PostHog's application state, we use Postgres in all of the ways you'd expect. In fact, at our start, we exclusively used Postgres until our analytical queries were frying it alive. We then added ClickHouse, a real-time analytical engine that powers our funnels, trends, retention, and paths over billions of events.
For a while, we were strictly a Postgres and ClickHouse stack and didn't envision needing another OLAP solution. However, as the needs of our customers grew, ClickHouse had constraints that meant it simply would not work for data warehousing for all of our customers.
So, we architected a managed data warehouse product that could scale in parallel and isn't tied to our ClickHouse resources. The managed warehouse is fundamentally different from the analytical products we offered before: instead of only providing analytics on customer data, it also provides a service to store, transform, model, and visualize all your data — not just what's ingested by other PostHog products. Essentially, our customers can now use us as a full data stack, not just an opinionated analytics service.
We wanted to make that data natively queryable, so we built a DuckDB layer to make it easy for our customers. But that posed a problem: if DuckDB is not a server, how should our customers actually access it?
To solve this, we built Duckgres, an open-source wrapper that wraps DuckDB in a Postgres server, making it compatible with anything that supports the PostgreSQL wire protocol. It effectively makes DuckDB look like a Postgres database to an external service. Tada! Now you can connect a DuckDB warehouse to any Postgres-compatible BI tool, dbt, or Postgres-service. Plus, it has a 10 out of 10 name.
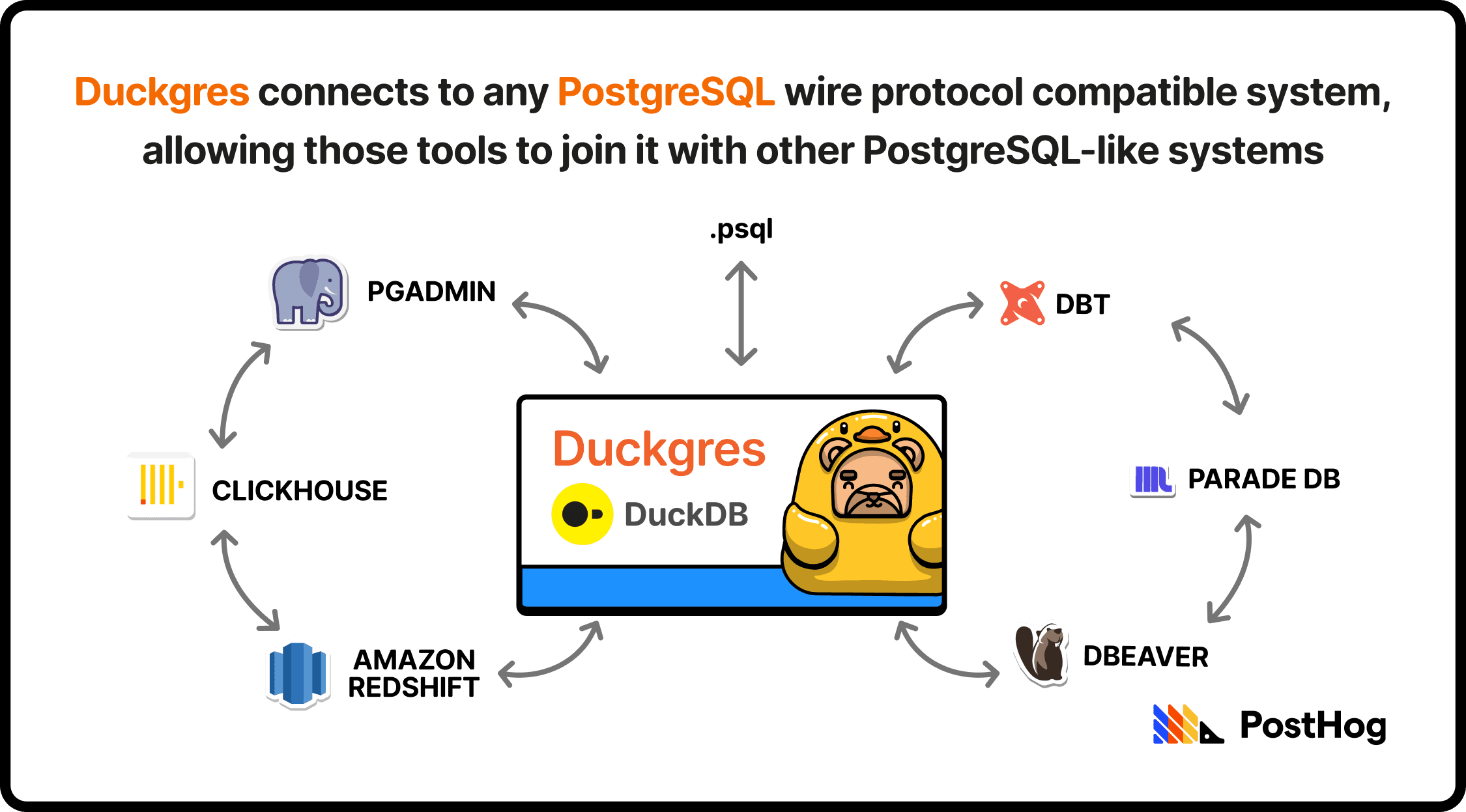
Duckgres also integrates with DuckLake, so that a DuckLake catalog is automatically added to any Duckgres connection. This sets up a nice trinity: DuckDB for easy querying, DuckLake for durable storage, and Duckgres for tight integrations with Postgres-ready systems.
If you're curious about trying PostHog's warehouse product, or even Duckgres, please give it a go!
Subscribe to our newsletter
build mode
Read by 75,000+ founders and builders
We'll share your email with Substack
PostHog is the leading platform for building self-driving products. With a full suite of developer tools – AI observability, product analytics, session replay, feature flags, experiments, error tracking, logs, and more – PostHog captures all the context agents need to diagnose problems, uncover opportunities, and ship fixes. A data warehouse and CDP tie it all together, unifying that context into one source agents can read across. You can steer it all from Slack, the web app, the desktop (PostHog Desktop), or your own editor via the MCP.