OpenRouter AI Observability installation
Contents
- 1
Install dependencies
RequiredFull working examplesSee the complete Node.js and Python examples on GitHub. If you're using the PostHog SDK wrapper instead of OpenTelemetry, see the Node.js wrapper and Python wrapper examples.
Install the OpenTelemetry SDK, the OpenAI instrumentation, and the OpenAI SDK.
- 2
Set up OpenTelemetry tracing
RequiredConfigure OpenTelemetry to auto-instrument OpenAI SDK calls and export traces to PostHog. PostHog converts
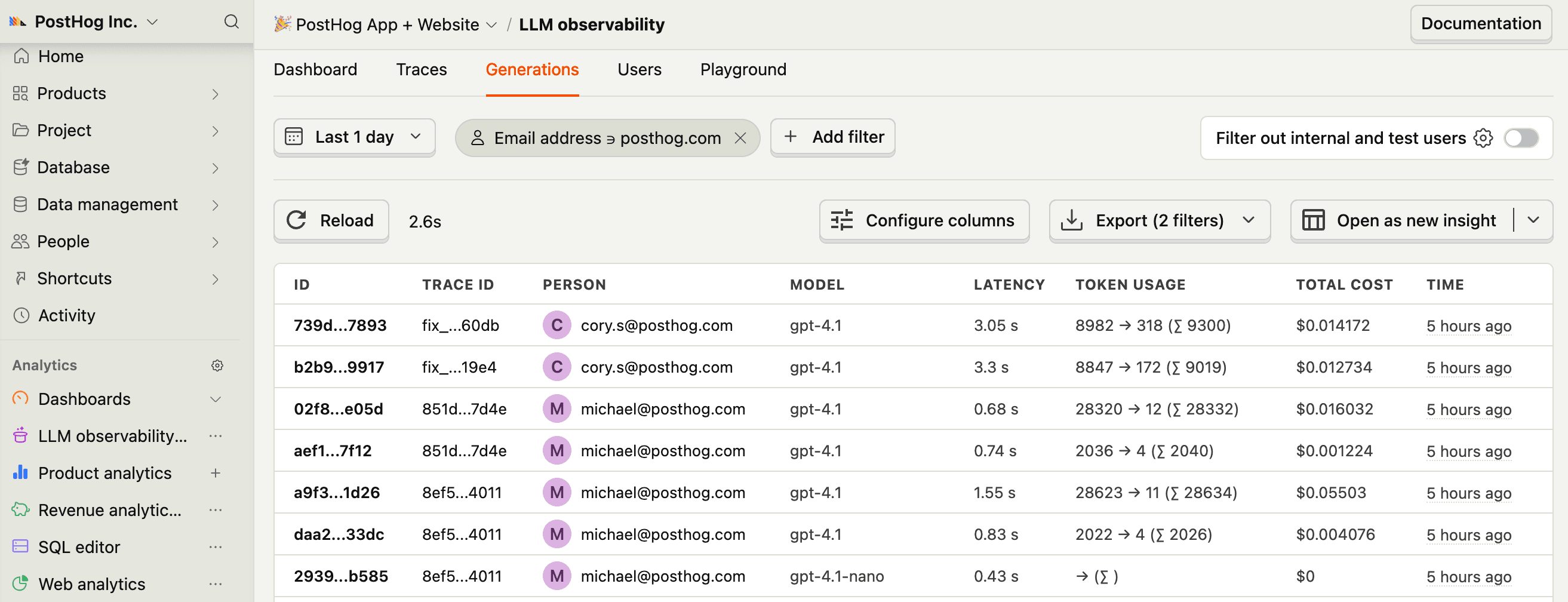
gen_ai.*spans into$ai_generationevents automatically. - 3
Call OpenRouter
RequiredNow, when you use the OpenAI SDK to call OpenRouter, PostHog automatically captures
$ai_generationevents via the OpenTelemetry instrumentation.Note: If you want to capture LLM events anonymously, omit the
posthog.distinct_idresource attribute. See our docs on anonymous vs identified events to learn more.You can expect captured
$ai_generationevents to have the following properties:Property Description $ai_modelThe specific model, like gpt-5-miniorclaude-4-sonnet$ai_latencyThe latency of the LLM call in seconds $ai_time_to_first_tokenTime to first token in seconds (streaming only) $ai_toolsTools and functions available to the LLM $ai_inputList of messages sent to the LLM $ai_input_tokensThe number of tokens in the input (often found in response.usage) $ai_output_choicesList of response choices from the LLM $ai_output_tokensThe number of tokens in the output (often found in response.usage)$ai_total_cost_usdThe total cost in USD (input + output) [...] See full list of properties - 4
Next steps
RecommendedNow that you're capturing AI conversations, continue with the resources below to learn what else AI Observability enables within the PostHog platform.
Resource Description Basics Learn the basics of how LLM calls become events in PostHog. Generations Read about the $ai_generationevent and its properties.Traces Explore the trace hierarchy and how to use it to debug LLM calls. Spans Review spans and their role in representing individual operations. Anaylze LLM performance Learn how to create dashboards to analyze LLM performance.