





What happens when changing distribution after rollout?
Contents
It helps to look at Experiments with two separate questions:
- Who sees what variant? (user perspective)
- Who is included in my analysis? (statistical perspective)
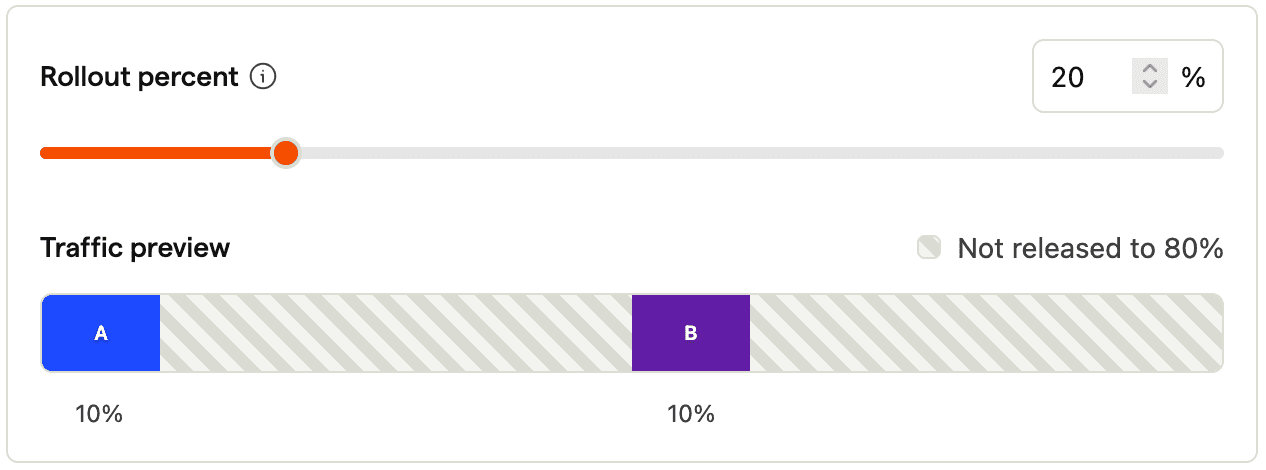
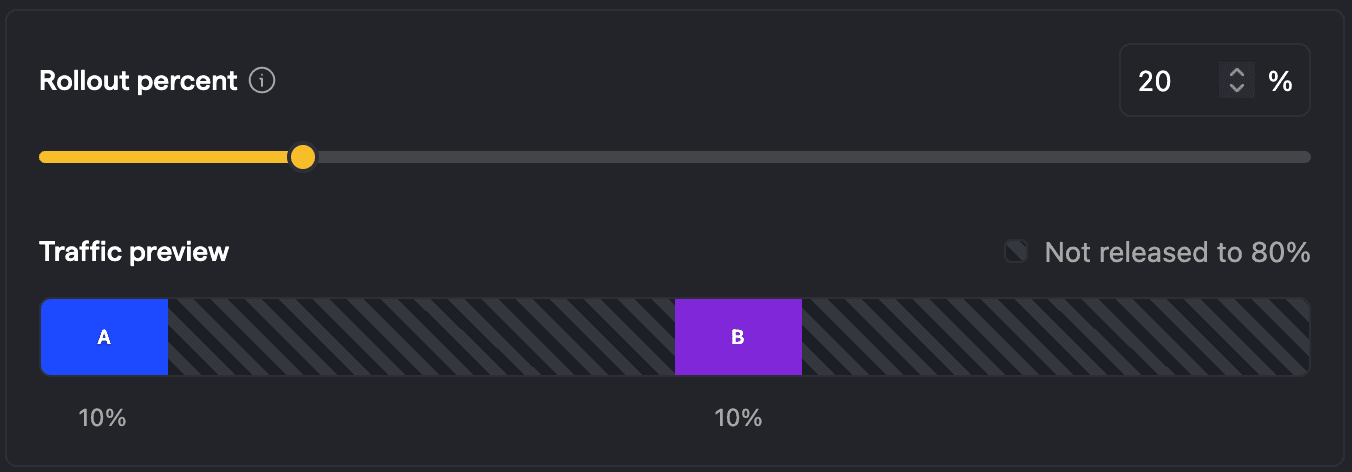
Example: Two variants with equal split and 20% rollout
Say you have two variants with equal split and 20% total rollout. How are the questions from above answered?
Since A is the control variant, which should be the current behavior as if there was no feature flag, 90% of users see the default behavior (80% outside of the experiment and 10% under A), while 10% of users see B. The analysis considers the users who have been exposed to the experiment, which is all users that have explicitly been assigned A or B with 10% each.
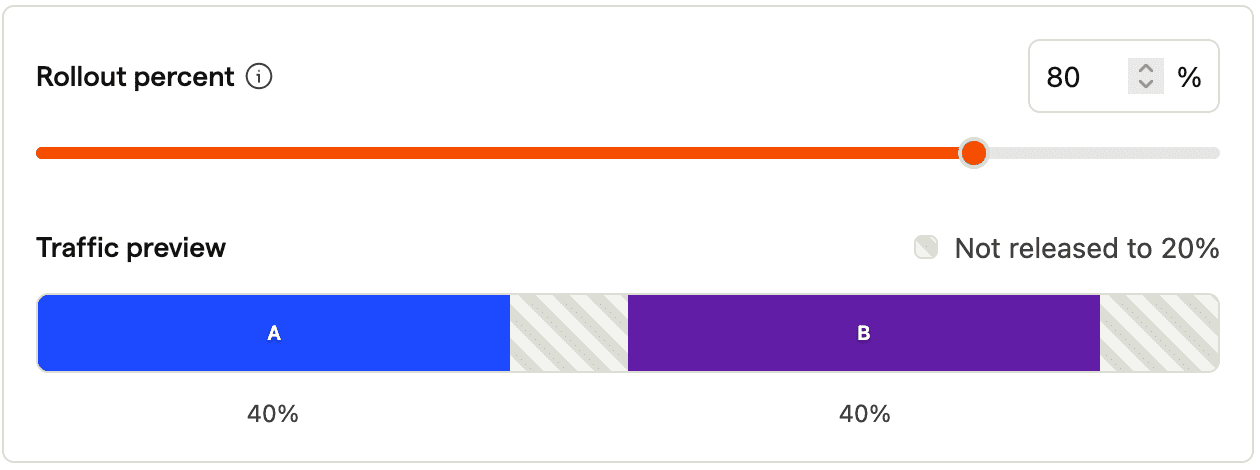
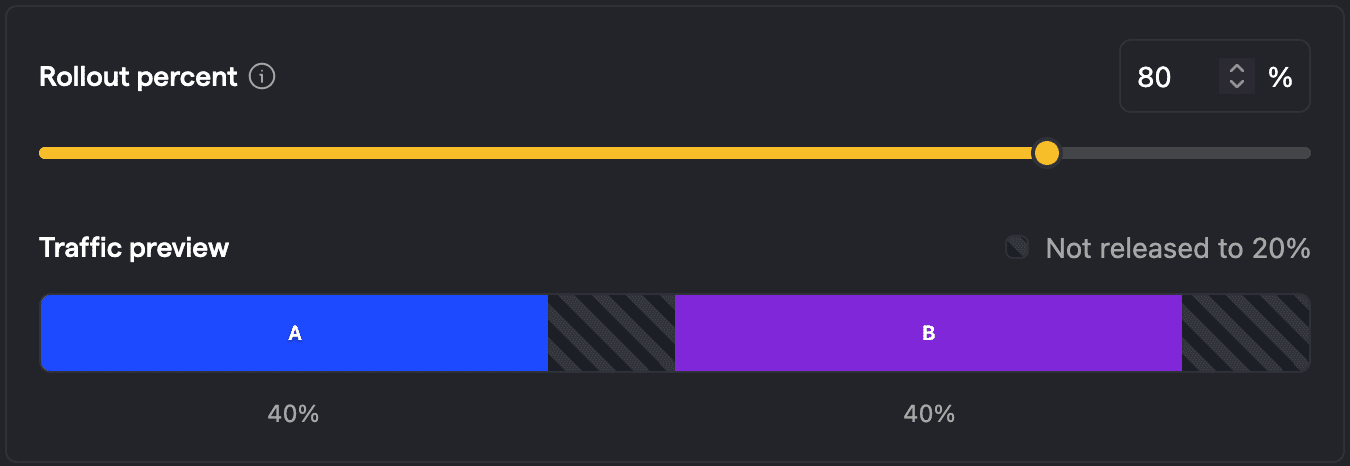
Increasing rollout
Now let's increase the rollout to 80%. On the user side, this only impacts users who are currently outside of the experiment and see the default behavior. An additional 60% of your total user base will be included in the experiment, 30% will be put in A (see default behavior), and 30% will be in B (and see the test variant). There will be no change for the users that were already in either A or B. 20% of users will still be outside of the experiment and see the default behavior.
The analysis now evaluates the behavior of 80% of users, 40% each. This is all stable as there is no reassignment of users. Visually speaking we don't see A now reaching into a prior area of B. The fact that we have users switching from default to B is the one we want to have, since we want to roll out the new variant B and measure its impact.
Revoking rollout
So what happens if we revoke the rollout to say 50%? Users that were earlier in A and B will now be taken out of the experiment. For users in A, they will still see the same, as A is configured to show the default variant. Whereas users in B that are taken out of the experiment will switch from seeing the test variant to the default behavior. (To be exact, this affects only some users in B: It's only the ones who fall under the part of the bucket that got removed and in fact have been online and navigated through the experiment before we changed it.)
Statistically speaking, users that have been exposed to B will also continue to be counted towards B. It gets clearer if we consider the most extreme case: To revoke rollout to 0%. In this case, the experiment still shows metrics given the prior exposures.
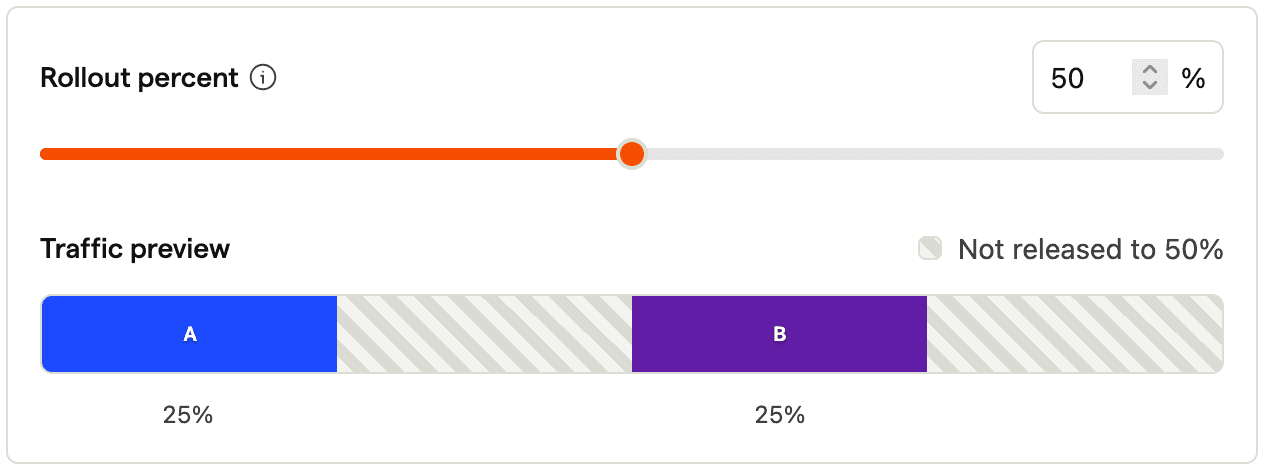
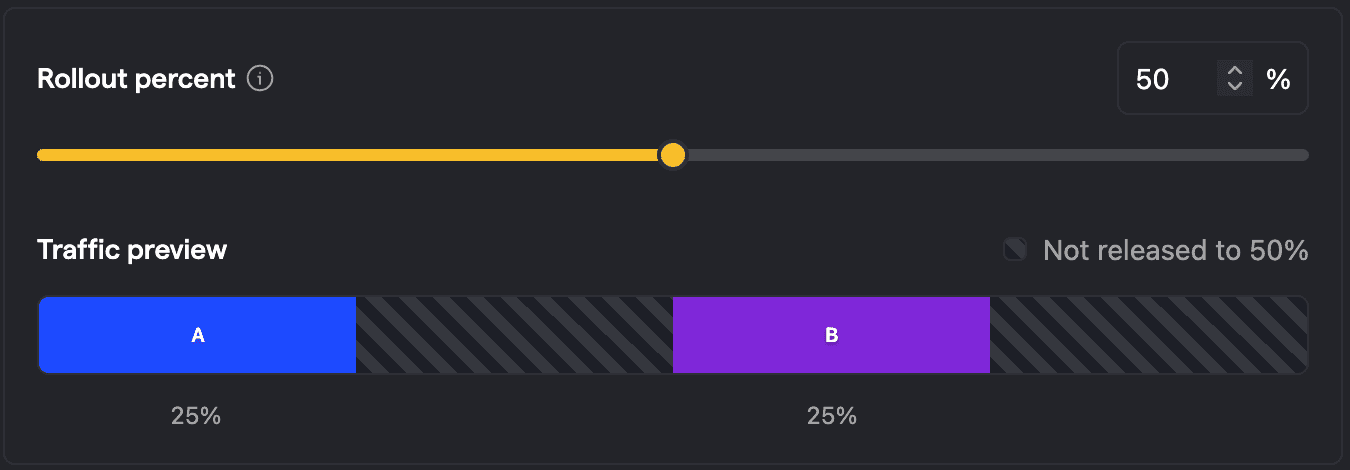
Anti-pattern: Changing split after rollout
Now let's look into some anti-patterns, which are about actually changing variant assignments. For example, we could change the split after rolling out the feature flag, for example to an 80/20 split between A/B. The below picture shows that this moves the buckets around which becomes problematic when we increase the rollout to say 100%, because users who have been exposed to B before will now not only see A again, but also be explicitly assigned to A.
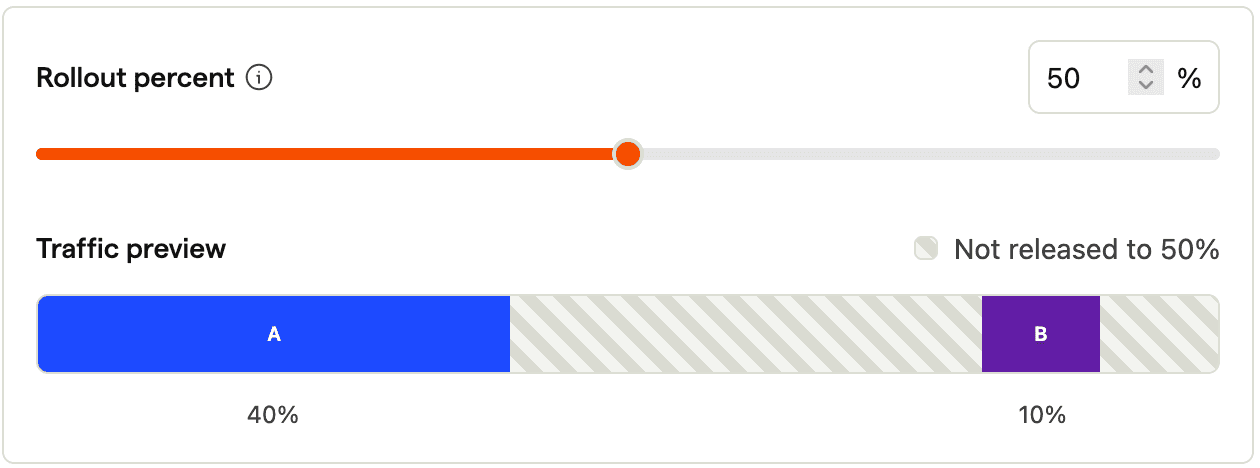
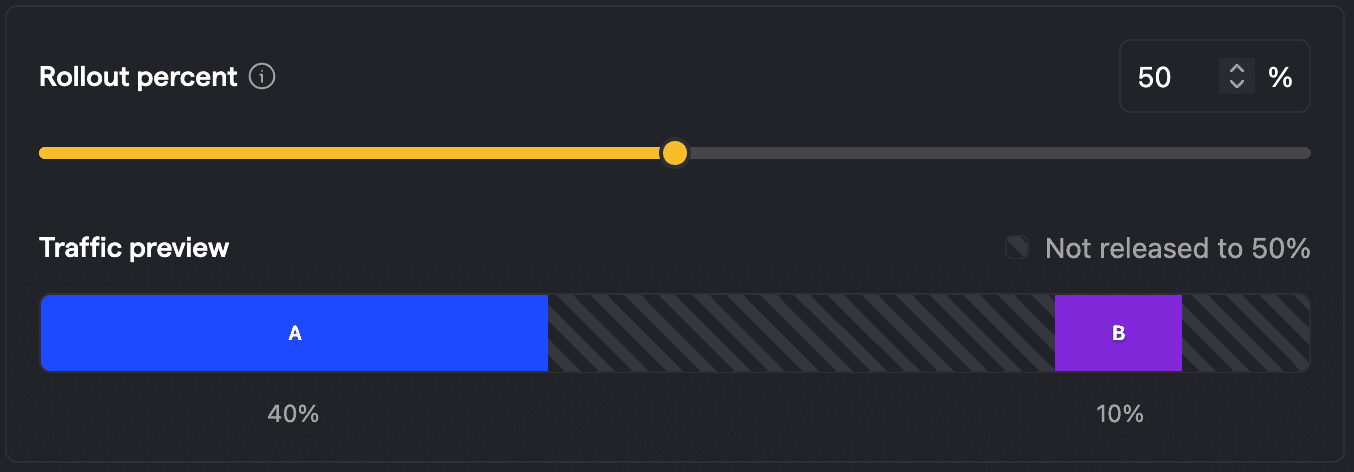
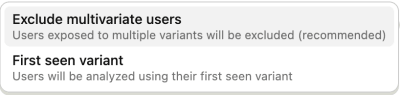
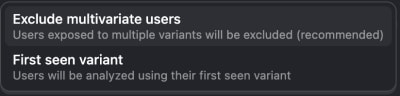
This is problematic for the analysis, as the behavior the user shows cannot be uniquely linked to one variant anymore. In other words, we have introduced bias. There are two options on how to deal with such cases: To exclude those users from the analysis (default and recommended), or to only consider the first seen variant. Even though it is recommended to exclude those noisy data points from the analysis, the reduction in data points also means that we need to wait longer for reaching a reliable measurement (as fewer data points mean higher uncertainty and variance).
Anti-pattern: Adding variants after rollout
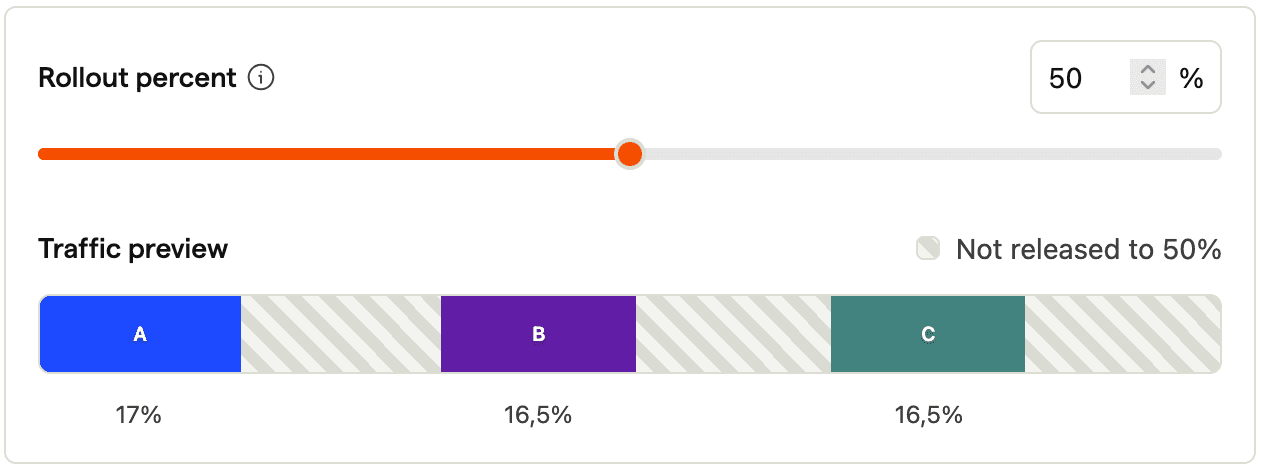
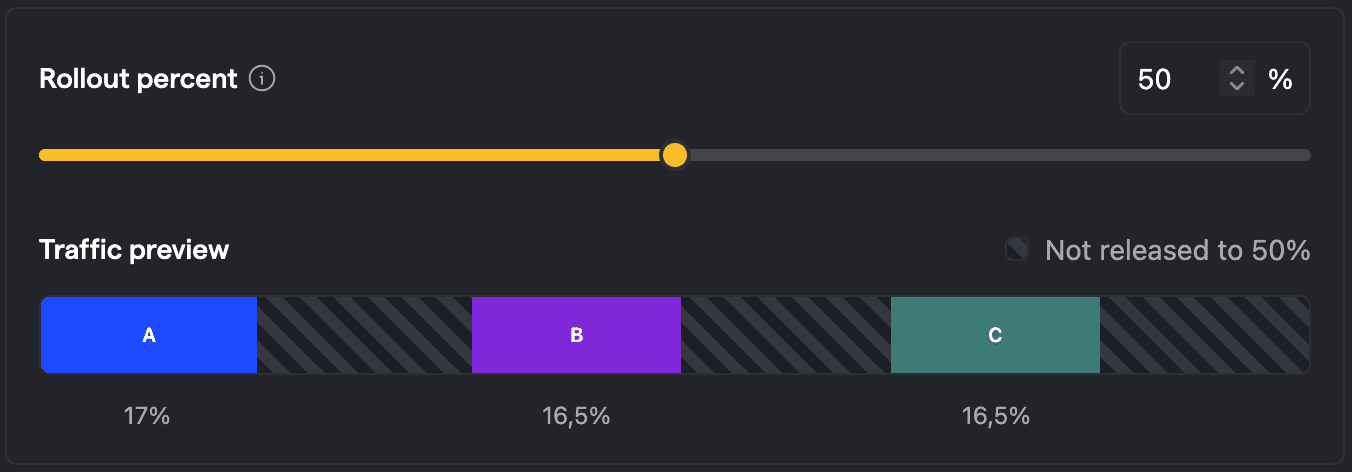
And lastly, adding variants after rollout. Now users might experience an array of variants, for example: First switching to B and now switching to C. This is likely a worse user experience than the cases above. It also leads to multivariate users which we recommend to exclude in the analysis. But now that we have even more variants, the impact is more severe: As a rule of thumb, the more variants we have, the more traffic we should have on this experiment, as otherwise the results will be unreliable. So adding a variant afterwards requires more traffic than what we initially needed, but at the same time we exclude traffic now.
How to get best results
With all this being said, what does the best experiment look like? We want to have test groups as neutral as they can be with as much exposure as possible. That means:
- No bias in the user groups, for example by where the experiment is placed
- No bias introduced through customizing criteria of who to include in the analysis
- Equal split between variants
- No changes after release rather than increasing the total rollout